Waterfalls are stunning by their very nature, so it's no surprise that engineers are a little obsessed with them. The old DOD-STD-2167A standard recommended using the waterfall model, and my legacy engineering background was based on the Phase-Gate model , which in my opinion is pretty darn similar to the waterfall model . On the other hand, those of us who studied computer science at university probably know that the waterfall model is in some way an anti-pattern . Our friends in the academic ivory tower tell us no, no, AgileIs the road to success and it looks like the industry has proven that claim to be true.
So, what should a developer choose between the aging waterfall model and the newfangled Agile? Does the equation change when it comes to developing algorithms? Or some security critical software?
As usual in life, the answer lies somewhere in between.
Hybrid, spiral and V-pattern
Hybrid development is the answer that sits in the middle. Where the waterfall model does not allow going back and changing requirements, the hybrid model does. And where Agile has problems with upfront design, hybrid development leaves room for it. Moreover, hybrid development aims to reduce the number of defects in the final product, which is what we probably want when designing algorithms for security-critical applications.
Sounds good, but how effective is it?
To answer this question, we are betting on hybrid development while working on the NDT localization algorithm.. Localization is an essential part of any self-driving stack that goes beyond pure reactive control. If you don't believe me or are unfamiliar with localization, I highly recommend that you take a look at some of the design documents that have been developed through this process.
So what is hybrid development in a nutshell? From my amateur point of view, I would say that this is an idealized V-shaped , or spiral model . You plan, design, implement, and test, and then iterate through the entire process based on the lessons learned and the new knowledge you have gained during that time.
Practical use
More specifically, we, with the NDT working group at Autoware.Auto, have completed our first descent down the left cascade of the V-model (i.e., made the first iteration through the design phase) in preparation for the Autoware Hackathon in London (run by Parkopedia !). Our first pass through the design phase consisted of the following steps:
- Literature review
- Overview of existing implementations
- Designing high-level components, use cases and requirements
- Fault analysis
- Definition of metrics
- API architecture and design
You can take a look at each of the resulting documents if you are interested in something similar, but for the rest of this post I will try to break down some of them, and also explain what and why came of it at each of these stages.
Review of literature and existing implementations
The first step in any decent endeavor (which is how I would classify an NDT implementation) is to see what other people have done. Humans are, after all, social beings, and all of our accomplishments stand on the shoulders of giants.
Allusions aside, there are two important areas to consider when considering the “art of the past”: academic literature and functional realizations.
It's always helpful to look at what poor graduate students were working on in the midst of the famine. At best, you will find that there is a perfectly excellent algorithm that you can implement instead of your own. In the worst case, you will gain an understanding of the space and variation of solutions (which can help information architecture), and you will also be able to learn about some of the theoretical underpinnings of the algorithm (and thus which invariants you should watch out for ).
On the other hand, it’s just as helpful to look at what other people are doing — after all, it’s always easiest to start doing something with a starting prompt. Not only can you borrow good architectural ideas for free, but you can also discover some of the guesses and dirty tricks you might need to get the algorithm to work in practice (and you might even be able to fully integrate them into your architecture).
From our review of the NDT literature , we have gathered the following useful pieces of information:
- The NDT family of algorithms has several variations:
- P2D
- D2D
- Limited
- Semantic - There are tons of dirty tricks that can be used to make the algorithm perform better.
- NDT is usually compared to ICP
- NDT is slightly faster and slightly more reliable.
- NDT operates reliably (has a high success rate) within a defined area
Nothing incredible, but this information can be saved for later use, both in design and implementation.
Likewise, from our overview of existing implementations, we saw not only concrete steps but also some interesting initialization strategies.
Use cases, requirements and mechanisms
An integral part of any design-or-plan-first development process is to address the problem you are trying to solve at a high level. In a broad sense, from the point of view of functional safety (which, I confess, I am far from an expert), the "high-level view of the problem" is organized approximately as follows:
- What use cases are you trying to solve?
- What are the requirements (or limitations) for a solution to satisfy the above use cases?
- What mechanisms meet the above requirements?
The process described above provides a disciplined high-level view of the problem and gradually becomes more detailed.
To get an idea of what this might look like, you can take a look at the high-level localization project document we put together in preparation for the development of the NDT. If you're not in the mood to read before bed, read on.
Use cases
I like three thought approaches to use cases (attention, I'm not a functional safety expert):
- What is the component supposed to do? (remember SOTIF !)
- What are the ways that I can enter input into a component? (input use cases, I like to call them upstream)
- What are the ways I can get the output? (weekend or top-down use cases)
- Bonus question: In what whole system architectures can this component reside?
Putting it all together, we came up with the following:
- Most algorithms can use localization, but ultimately they can be divided into flavors that work both locally and globally.
- Local algorithms need continuity in their transformation history.
- Almost any sensor can be used as a source of localization data.
- We need a way to initialize and troubleshoot our localization methods.
Apart from the various use cases you can think of, I also like to think of some common use cases that are very strict. To do this, I have the option (or task) of a completely unmanned off-road trip, passing through several tunnels with traffic in a caravan. There are a couple of annoyances with this use case like accumulation of odometry errors, floating point errors, localization corrections, and outages.
Requirements
The purpose of developing use cases, in addition to generalizing any problem you are trying to solve, is to define requirements. In order for a use case to take place (or be satisfied), there are probably some factors that must be realized or possible. In other words, each use case has a specific set of requirements.
In the end, the general requirements for a localization system are not that scary:
- Provide transformations for local algorithms
- Provide transformations for global algorithms
- Provide the mechanism for initialization of relative localization algorithms
- Ensure conversions don't spill over
- Ensure REP105 compliance
Qualified functional safety specialists are likely to formulate many more requirements. The value of this work lies in the fact that we clearly formulate certain requirements (or restrictions) for our design, which, like mechanisms, will satisfy our requirements for the operation of the algorithm.
Mechanisms
The end result of any kind of analysis should be a practical set of lessons or materials. If as a result of the analysis we cannot use the result (even a negative one!), Then the analysis was wasted.
In the case of a high-level engineering document, we are talking about a set of mechanisms or a construct that encapsulates these mechanisms, which can adequately suit our use cases.
This specific high-level localization design allowed for the set of software components, interfaces, and behaviors that make up the architecture of the localization system. A simple block diagram of the proposed architecture is shown below.
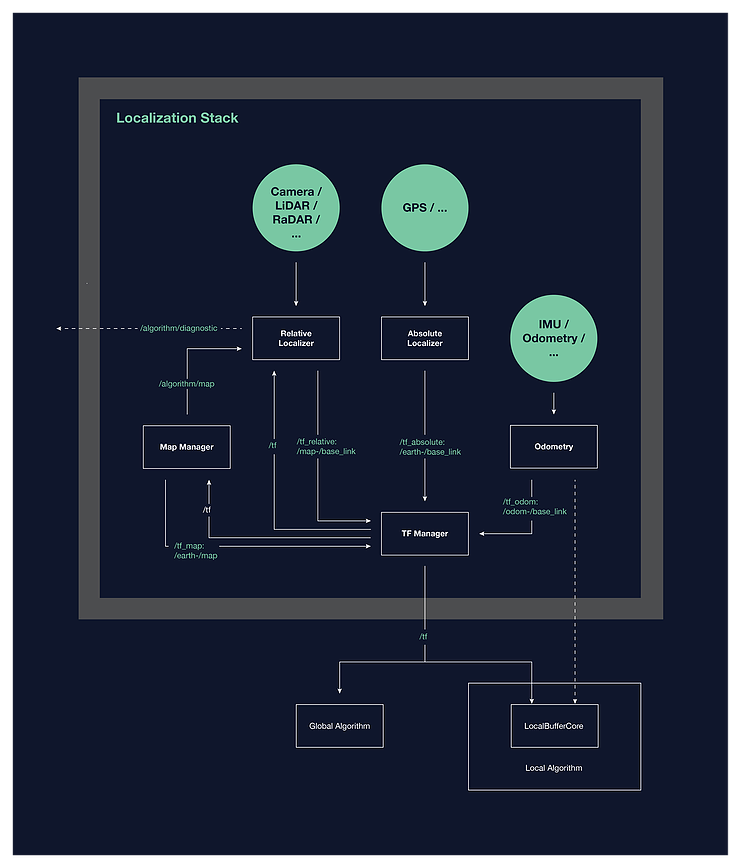
If you are interested in more information about architecture or design, I highly recommend that you readthe full text of the document .
Fault analysis
Since we are building components on security-critical systems, failures are something we should try to avoid, or at least mitigate. Therefore, before we try to design or build anything, we should at least be aware of how things can break.
When analyzing faults, as in most cases, it is useful to look at a component from multiple angles. To analyze the failures of the NDT algorithm, we considered it in two different ways: as a general (relative) localization mechanism, and specifically as an instance of the NDT algorithm.
When viewed from the point of view of the localization mechanism, the main failure mode is formulated as follows - "what to do if the input is incorrect data?" Indeed, from the point of view of an individual component, little can be done except to conduct a basic check on the adequacy of the system. At the system level, you have additional options (for example, enabling security features).
Considering NDT as an algorithm in isolation, it is useful to abstract from the algorithm by highlighting the appropriate number of aspects. It will be helpful to pay attention to the pseudocode version of the algorithm (this will help you, the developer, understand the algorithm better). In this case, we analyzed the algorithm in detail and studied all situations in which it can break.
An implementation error is a perfectly reasonable failure, although it can be fixed with appropriate testing. Some nuances regarding numerical algorithms began to appear a little more often and more insidiously. In particular, we are talking about finding inverse matrices or, more generally, solving systems of linear equations, which can lead to numerical errors. This is a very sensitive failure scenario and should be addressed.
Two other important failures that we also identified are verifying that certain expressions are not unlimited in magnitude (floating point precision control), and verifying that the magnitude or size of inputs is constantly monitored.
In total, we have developed 15 recommendations. I would recommend that you familiarize yourself with them.
I will also add that although we did not use this method, the fault tree analysis is an excellent tool for structuring and quantifying the problem of failure analysis.
Definition of metrics
"What is measured is manageable"Unfortunately, in professional development, it's not enough to shrug your shoulders and say “done” when you're tired of working on something. Basically, any work package (which again is an NDT development) requires acceptance criteria, which must be agreed upon by both the customer and the supplier (if you are both the customer and the seller, skip this step). All the jurisprudence exists to support these aspects, but as engineers we can simply cut out the middlemen by creating metrics to determine the availability of our components. After all, the numbers are (mostly) unambiguous and irrefutable.
- Popular phrase of managers
Even if acceptance criteria are unnecessary or irrelevant, it's still nice to have a well-defined set of metrics that characterize and improve the quality and performance of a project. In the end, what is being measured is controllable.
For our NDT implementation, we split the metrics into four broad groups:
- General software quality metrics
- Common Firmware Quality Metrics
- General metrics of the algorithm
- Localization-specific metrics
I won't go into details because these metrics are all relatively standard. The important thing is that the metrics have been defined and identified for our specific problem, which is roughly what we can achieve as developers of an open source project. Ultimately, the bar for acceptance should be determined based on the specifics of the project by those deploying the system.
The last thing I will repeat here is that while metrics are fantastic to test, they are not a substitute for checking implementation understanding and usage requirements.
Architecture and API
After painstakingly defining the problem we are trying to solve and building an understanding of the solution space, we can finally dive into the area that borders on implementation.
I've been a fan of test- driven development lately . Like most engineers, I love the development process, and the idea of writing tests seemed cumbersome to me in the first place. When I started programming professionally, I went straight ahead and did testing after development (even though my university professors told me to do the opposite). Researchshow that writing tests before implementation tends to result in fewer bugs, higher test coverage, and generally better code. Perhaps more importantly, I believe that test-driven development helps address the big problem of algorithm implementation.
What does it look like?
Instead of introducing a monolithic ticket called "Implement NDT" (including tests), which will result in several thousand lines of code (which cannot be effectively viewed and studied), you can break the problem into more meaningful fragments:
- Write classes and public methods for an algorithm (create an architecture)
- Write tests for the algorithm using the public API (they should fail!).
- Implement the logic of the algorithm
So the first step is to write the architecture and API for the algorithm. I'll cover the other steps in another post.
While there are many works out there that talk about how to "create architecture", it seems to me that designing software architecture has something to do with black magic. Personally, I like to think of thinking about software architecture as drawing boundaries between concepts and trying to characterize the degrees of freedom in posing a problem and how to solve it in terms of concepts.
What, then, are the degrees of freedom in NDT?
A review of the literature tells us that there are different ways of presenting scans and observations (eg P2D-NDT and D2D-NDT). Likewise, our high-level engineering paper says that we have several ways to represent the map (static and dynamic), so this is also a degree of freedom. More recent literature also suggests that the optimization problem may be revisited. However, comparing the practical implementation and the literature, we see that even the details of the optimization solution may differ.
And the list goes on and on.
Based on the results of the initial design, we settled on the following concepts:
- Optimization problems
- Optimization solutions
- Scan view
- Map view
- Initial hypothesis generation systems
- Algorithm and node interfaces
With some subdivision inside these items.
The ultimate expectation of an architecture is that it should be extensible and maintainable. Whether our proposed architecture lives up to this hope, only time will tell.
Further
After design, of course, it is time for implementation. Official work on the implementation of NDT in Autoware.Auto was carried out at the Autoware hackathon organized by Parkopedia .
It should be reiterated that what has been presented in this text is only the first pass through the design phase. Knownthat no battle plan holds up to facing the enemy, and the same can be said for software design. The final failure of the waterfall model was carried out on the assumption that the specification and design were perfect. Needless to say, neither the specification nor the design is perfect, and as implementation and testing progresses, flaws will be discovered and changes will have to be made to the designs and documents outlined here.
And that's okay. We, as engineers, are not our work or identify with it, and all we can try to do is iterate and strive for perfect systems. After all that has been said about the development of the NDT, I think we have made a good first step.
Subscribe to channels:
@TeslaHackers — Tesla-, Tesla
@AutomotiveRu — ,

- automotive . 2500 , 650 .
, , . ( 30, ), -, -, - (DSP-) .
, . , , , . , automotive. , , .
, , . ( 30, ), -, -, - (DSP-) .
, . , , , . , automotive. , , .
:
- - Automotive, Aerospace, (50+)
- [] (, , )
- DEF CON 2018-2019
- [] Motornet —
- 16 , 8
- open source
- McKinsey: automotive
- …