
Here you will find a list of materials released in June in English. All of them are written without excessive academicism, contain code examples and links to non-empty repositories. Most of the technologies mentioned are in the public domain and do not require heavy-duty hardware for testing.
Image GPT
Open AI decided that since a transformer model trained on text can generate coherent complete sentences, if the model is trained on sequences of pixels, it can generate augmented images. Open AI demonstrates how high-quality sampling and accurate image classification allows the generated model to compete with the best convolutional models in unsupervised learning environments.

Face depixelizer
A month ago we were given the opportunity to play with the tool, which uses a machine learning model to transform portraits into beautiful pixel art. It's fun, but it's hard to imagine the widespread use of this technology yet. But the tool that produces the opposite effect immediately became very interested in the public. With the help of a face depixelizer, in theory, it will be possible to establish the identity of a person by video recording from outdoor surveillance cameras.

DeepFaceDrawing
If working with pixel images is not enough, and you need to compose a photograph with a portrait of a person from a primitive sketch, then a tool based on DNN has already appeared for this. As conceived by the creators, only general outlines are needed, and not professional sketches - the model will then itself restore the person's face, which will coincide with the sketch. The system was created using the Jittor framework, as the creators promise, the source code for Pytorch will soon be added to the project repository.
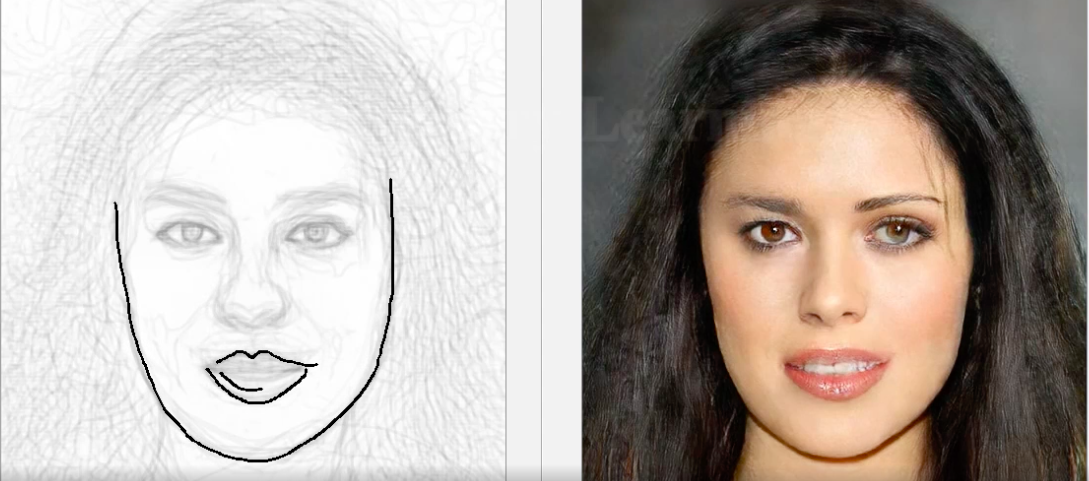
PIFuHD
With facial reconstructions sorted out, what about the rest of the body? Thanks to the development of DNN, it became possible to 3D-model a human figure based on a two-dimensional photo. The main limitation was due to the fact that accurate predictions require analysis of a wider context and source data in high resolution. The model's layered architecture and end-to-end learning capabilities will help solve this problem. At the first level, to save resources, the entire image is analyzed in low resolution. The context is then formed, and at a more detailed level, the model evaluates the geometry by analyzing the high-resolution image.

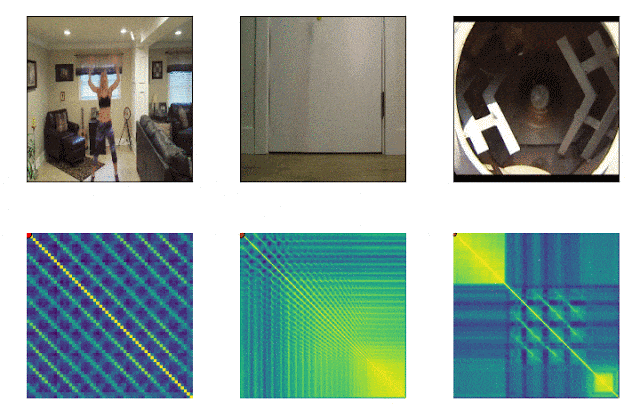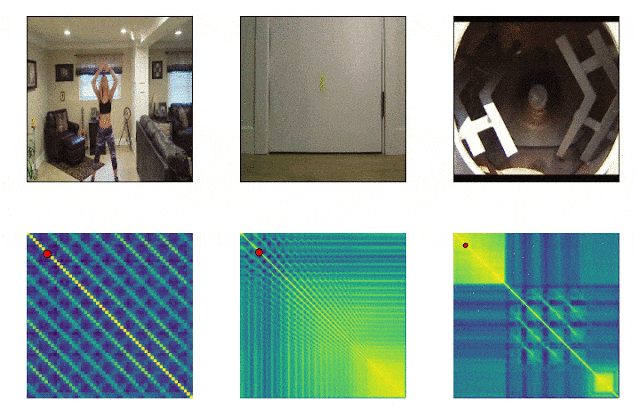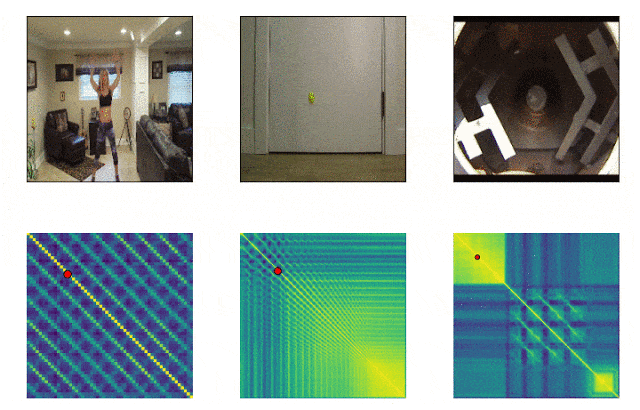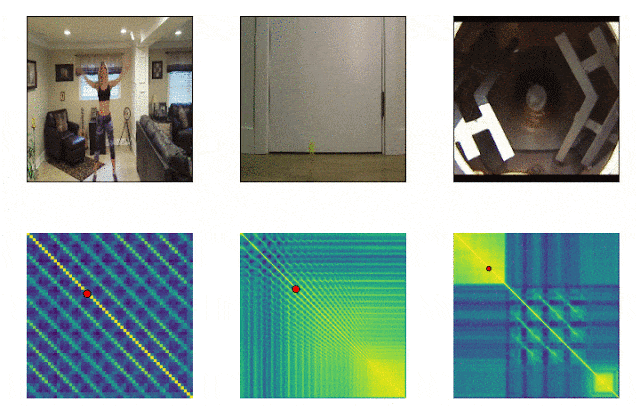
RepNet
Many things that surround us consist of cycles of different frequency. Often, in order to understand the essence of a phenomenon, it is necessary to analyze information about its recurring manifestations. Taking into account the possibilities of video shooting, it is no longer difficult to fix the repetitions, the problem was in counting them. The method of frame-by-frame comparison of pixel density in the frame was often not suitable due to camera shake, or obstruction by objects, as well as a sharp difference in scale and shape when zooming in and out. A model developed by Google now solves this problem. It identifies repetitive actions in the video, including those that were not used in training. As a result, the model returns data on the frequency of repeated actions recognized in the video. Colab is already available .
SPICE model
Previously, you had to rely on sophisticated signal processing algorithms to determine the pitch. The biggest challenge was separating the sound under study from background noise or the sound of accompanying instruments. A pre-trained model is now available for this task that detects high and low frequencies. The model is available for use on the web and mobile devices.
Social distancing detector
The case of creating a program with which you can track whether people observe social distancing. The author tells in detail how he chose a pre-trained model, how he coped with the task of recognizing people, and how, using OpenCV, he transformed the image into an orthographic projection to calculate the distance between people. You can also see the project source code in detail .

Recognition of typical documents
Today, there are thousands of variations of the most common template documents such as receipts, invoices and checks. Existing automated systems that are designed to work with a very limited type of template. Google suggests using machine learning for this. The article discusses the architecture of the model and the results of the obtained data. The tool will soon become part of the Document AI service .
How to create a scalable pipeline for the development and deployment of machine learning algorithms for contactless retail
Israeli startup Trigo shares its experience of using machine learning and computer vision for take-and-go retail. The company is a supplier of a system that allows stores to operate without a cash register. The authors tell what tasks they faced and explain why they chose PyTorch as a framework for machine learning, and Allegro AI Trains for infrastructure and how they managed to establish the development process.
That's all, thank you for your attention!