Today I want to talk about something else - about something that in no way belongs to best practices, with the help of which it is very easy to shoot yourself in the foot and make a previously executed query slower, or no longer execute at all due to an error ... It's about hints and plan guides.
Hints are hints to the query optimizer, a complete list can be found on MSDN . Some of them are really hints (for example, you can specify OPTION (MAXDOP 4)) so that the query can be executed with max degree of parallelism = 4, but there is no guarantee that SQL Server will generate a parallel plan with this hint at all.
The other part is a direct guide to action. For example, if you write OPTION (HASH JOIN), then SQL Server will build a plan without NESTED LOOPS and MERGE JOINs. And you know what will happen if it turns out that it is impossible to build a plan with only hash joins? The optimizer will say so - I cannot build a plan and the query will not be executed.
The problem is that it is not known for certain (at least to me) which hints are hints that the optimizer can hammer into; and which hints are guide hints that can cause the request to crash if something goes wrong. Surely there is already some ready-made collection where this is described, but this is in any case not official information and may change at any time.
Plan Guide is such a thing (which I don't know how to translate correctly) that allows you to bind a specific set of hints to a specific request, the text of which you know. This may be relevant if you cannot directly influence the request text that is generated by the ORM, for example.
Both hints and plan guides are by no means best practices, rather it is good practice to omit hints and these guides, because the distribution of data can change, data types can change and a million more things can happen, due to which your queries with hints will work worse than without them, and in some cases will stop working altogether. You must be one hundred percent aware of what you are doing and why.
Now a small explanation of why I even got into this.
I have a wide table with a bunch of nvarchar fields of different sizes - from 10 to max. And there are a bunch of queries to this table, which CHARINDEX searches for occurrences of substrings in one or more of these columns. For example, there is a request that looks like this:
SELECT *
FROM table
WHERE CHARINDEX(N' ', column)>1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET x ROWS FETCH NEXT y ROWS ONLYThe table has a clustered index on Id and a non-unique non-clustered index on column. As you yourself understand, there is zero sense from all this, since in WHERE we use CHARINDEX, which is definitely not SARGable. To avoid potential problems with the SB, I will simulate this situation on the open database StackOverflow2013, which can be found here .
Consider the dbo.Posts table, which has only a clustered index by Id and a query like this:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLYTo match my real database, I create an index on the Title column:
CREATE INDEX ix_Title ON dbo.Posts (Title);As a result, of course, we get an absolutely logical execution plan, which consists of scanning the clustered index in the opposite direction:
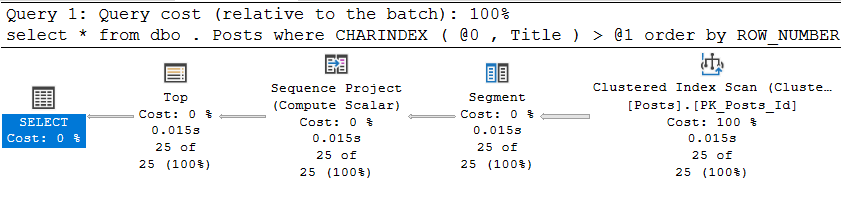

And it, admittedly, is performed quite well:
Table 'Posts'. Scan count 1, logical reads 516, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 16 ms
But what happens if, instead of the common word 'Data', we look for something rarer? For example, N'Aptana '(no idea what it is). The plan, of course, will remain the same, but the execution statistics, ahem, will change somewhat:
Table 'Posts'. Scan count 1, logical reads 253191, physical reads 113, read-ahead reads 224602, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 2563 ms
And this is also logical - the word is much less common and SQL Server has to scan a lot more data to find 25 rows with it. But somehow it's not cool, right?
And I was creating a non-clustered index. Maybe it would be better if SQL Server uses it? He himself will not use it, so I add a hint:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
OPTION (TABLE HINT (dbo.Posts, INDEX(ix_Title)));And, something is somehow completely sad. Execution statistics:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Posts'. Scan count 5, logical reads 109312, physical reads 5, read-ahead reads 104946, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 35031 ms
and the plan:

Now the execution plan is parallel and it has two sorts, both of them with spills in tempdb. By the way, pay attention to the first sort, which is performed after a non-clustered index scan, before Key Lookup - this is a special SQL Server optimization that tries to reduce the number of Random I / O - key lookups are performed in ascending order of the clustered index key. You can read more about this here .
The second sort is needed to select 25 lines in descending order Id. By the way, SQL Server might have guessed that it will have to sort by Id again, only in descending order and do key lookups in the "opposite" direction, sorting in descending order, not ascending, of the clustered index key at the beginning.
I do not provide statistics on the execution of a query with a hint on a nonclustered index with a search by the entry 'Data'. On my half-dead hard drive in a laptop, it took more than 16 minutes and I did not think of taking a screenshot. Sorry, I don't want to wait that long anymore.
But what about the request? Is a clustered index scan the ultimate dream, and you can't do anything faster?
What if I tried to avoid all sorts, I thought and created a nonclustered index, which, in general, contradicts what is usually considered the best practices for nonclustered indexes:
CREATE INDEX ix_Id_Title ON dbo.Posts (Id DESC, Title);Now we use the hint to tell SQL Server to use it:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
OPTION (TABLE HINT (dbo.Posts, INDEX(ix_Id_Title)));Oh, it worked well:

Table 'Posts'. Scan count 1, logical reads 6259, physical reads 0, read-ahead reads 7816, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1734 ms
The gain in processor time is not great, but you have to read much less - not bad. What about the frequent 'Data'?
Table 'Posts'. Scan count 1, logical reads 208, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms
Wow, that's good too. Now, since the request comes from the ORM and we cannot change its text, we need to figure out how to "nail" this index to the request. And the plan guide comes to the rescue.
The sp_create_plan_guide ( MSDN ) stored procedure is used to create a plan guide .
Let's consider it in detail:
sp_create_plan_guide [ @name = ] N'plan_guide_name'
, [ @stmt = ] N'statement_text'
, [ @type = ] N'{ OBJECT | SQL | TEMPLATE }'
, [ @module_or_batch = ]
{
N'[ schema_name. ] object_name'
| N'batch_text'
| NULL
}
, [ @params = ] { N'@parameter_name data_type [ ,...n ]' | NULL }
, [ @hints = ] {
N'OPTION ( query_hint [ ,...n ] )'
| N'XML_showplan'
| NULL
} name - clear, unique plan guide name
stmt- this is the request to which you need to add the hint. It is important to know here that this request must be written EXACTLY the same as the request that comes from the application. Odd space? The Plan Guide will not be used. Wrong line break? The Plan Guide will not be used. To make things easier for yourself, there is a "life hack" to which I will return a little later (and which I found here ).
type - indicates where the request specified in stmt. If it is part of a stored procedure, it should be OBJECT; if this is part of a batch from several requests, or it is an ad-hoc request, or a batch from one request, there should be SQL. If TEMPLATE is indicated here, this is a separate story about query parameterization, which you can read about on MSDN .
@module_or_batch depends ontype... If atype= 'OBJECT', this should be the name of the stored procedure. If atype= 'BATCH' - there should be the text of the entire batch, specified word-for-word with what comes from applications. Odd space? Well, you already know. If it is NULL, then we consider that this is a batch from one request and it matches what is specified instmt with all restrictions.
params- all parameters that are passed to the request along with data types should be listed here.
@hints is finally the nice part, here you need to specify which hints to add to the request. Here you can explicitly insert the required execution plan in XML format, if any. This parameter can also be NULL, which will lead to the fact that SQL Server will not use hints that are explicitly specified in the query instmt.
So, we create a Plan Guide for the query:
DECLARE @sql nvarchar(max) = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N''Data'', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY';
exec sp_create_plan_guide @name = N'PG_dboPosts_Index_Id_Title'
, @stmt = @sql
, @type = N'SQL'
, @module_or_batch = NULL
, @params = NULL
, @hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'And we try to execute the request:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLYWow, it worked:
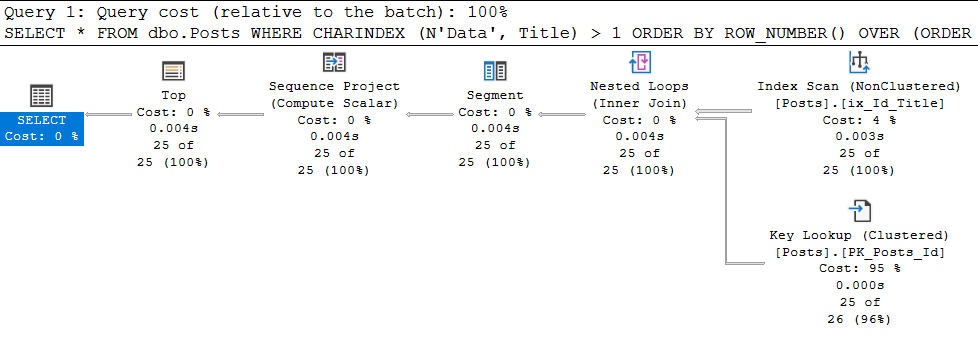
In the properties of the last SELECT statement, we see:

Great, the plan giude has been applied. What if you search for 'Aptana' now? And everything will be bad - we will again return to the scan of the clustered index with all the consequences. Why? And because, the plan guide is applied to a SPECIFIC query, the text of which coincides one to one with the executing one.
Luckily for me, most of the requests on my system come in parameterized. I didn’t work with non-parameterized queries and I hope I don’t have to. For them, you can use templates (see a little higher about TEMPLATE), you can enable FORCED PARAMETERIZATION in the database ( do not do this without understanding what you are doing !!! ) and, perhaps, after that, you will be able to link the Plan Guide. But I really haven't tried it.
In my case, the request is executed in something like this:
exec sp_executesql
N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;'
, N'@p0 nvarchar(250), @p1 int, @p2 int'
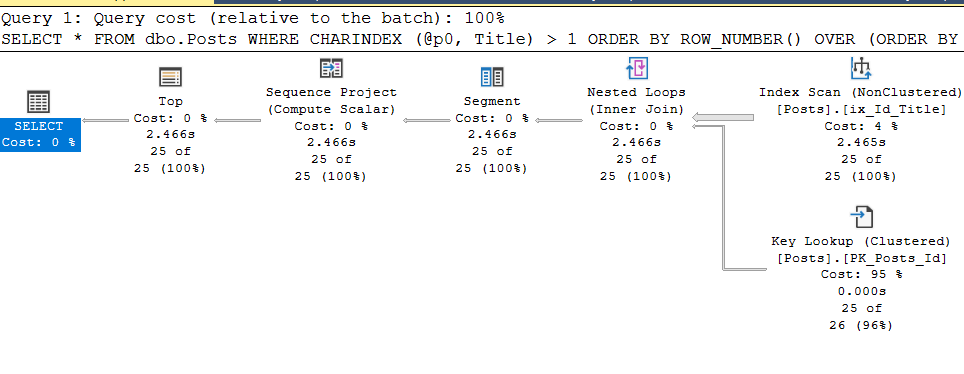
, @p0 = N'Aptana', @p1 = 0, @p2 = 25;Therefore, I create a corresponding plan guide:
DECLARE @sql nvarchar(max) = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;';
exec sp_create_plan_guide @name = N'PG_paramters_dboPosts_Index_Id_Title'
, @stmt = @sql
, @type = N'SQL'
, @module_or_batch = NULL
, @params = N'@p0 nvarchar(250), @p1 int, @p2 int'
, @hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'And, hurray, everything works as required:

Being outside the greenhouse conditions, it is not always possible to correctly specify the parameterstmtto attach a plan guide to a request, and for this there is a "life hack" that I mentioned above. We clear the plan cache, delete the guides, execute the parameterized query again and get its execution plan and its plan_handle from the cache.
A request for this can be used, for example, like this:
SELECT qs.plan_handle, st.text, qp.query_plan
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text (qs.sql_handle) st
CROSS APPLY sys.dm_exec_query_plan (qs.plan_handle) qp
We can now use the sp_create_plan_guide_from_handle stored procedure to create a plan guide from an existing plan.
It takes as parametersname- the name of the created guide, @plan_handle - the handle of the existing execution plan and @statement_start_offset - which defines the beginning of the statement in the batch for which the guide should be created.
Trying:
exec sp_create_plan_guide_from_handle N'PG_dboPosts_from_handle'
, 0x0600050018263314F048E3652102000001000000000000000000000000000000000000000000000000000000
, NULL;And now in SSMS we look at what we have in Programmability -> Plan Guides:

Now the current execution plan is "nailed" to our request, using the Plan Guide 'PG_dboPosts_from_handle', but, best of all, now it, like almost any object in SSMS, we can script and recreate the way we need it.
RMB, Script -> Drop AND Create and we get a ready-made script in which we need to replace the value of the @hints parameter with the one we need, so as a result we get:
USE [StackOverflow2013]
GO
/****** Object: PlanGuide PG_dboPosts_from_handle Script Date: 05.07.2020 16:25:04 ******/
EXEC sp_control_plan_guide @operation = N'DROP', @name = N'[PG_dboPosts_from_handle]'
GO
/****** Object: PlanGuide PG_dboPosts_from_handle Script Date: 05.07.2020 16:25:04 ******/
EXEC sp_create_plan_guide @name = N'[PG_dboPosts_from_handle]', @stmt = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY', @type = N'SQL', @module_or_batch = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;',
@params = N'@p0 nvarchar(250), @p1 int, @p2 int',
@hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'
GOWe execute and re-execute the request. Hooray, everything works:

If you replace the parameter value, everything works the same way.
Please note that only one guide can correspond to one statement. If you try to add another guide to the same statement, you will receive an error message.
Msg 10502, Level 16, State 1, Line 1
Cannot create plan guide 'PG_dboPosts_from_handle2' because the statement specified bystmtand @module_or_batch, or by @plan_handle and @statement_start_offset, matches the existing plan guide 'PG_dboPosts_from_handle' in the database. Drop the existing plan guide before creating the new plan guide.
The last thing I would like to mention is the sp_control_plan_guide stored procedure .
With its help, you can delete, disable and enable Plan Guides - both one at a time, indicating the name, and all the guides (I'm not sure - everything at all. Or everything in the context of the database in which the procedure is executed) - values are used for this @operation parameter - DROP ALL, DISABLE ALL, ENABLE ALL. An example of using HP for a specific plan is given just above - a specific Plan Guide with the specified name is deleted.
Was it possible to do without hints and a plan guide?
In general, if it seems to you that the query optimizer is stupid and does some kind of game, and you know how best, with a probability of 99% you are doing some kind of game (as in my case). However, in the case when you do not have the ability to directly influence the request text, a plan guide that allows you to add a hint to the request can be a lifesaver. Suppose we have the ability to rewrite the request text as we need it - can this change something? Sure! Even without the use of "exotic" in the form of full-text search, which, in fact, should be used here. For example, such a query has a completely normal (for a query) plan and execution statistics:
;WITH c AS (
SELECT p2.id
FROM dbo.Posts p2
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
)
SELECT p.*
FROM dbo.Posts p
JOIN c ON p.id = c.id;
Table 'Posts'. Scan count 1, logical reads 6250, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1500 ms
SQL Server first finds the required 25 identifiers by the ix_Id_Title index, and only then does a search in the clustered index using the selected identifiers - even better than with the guide! But what happens if we execute a query on 'Data' and display 25 lines, starting from the 20,000th line:
;WITH c AS (
SELECT p2.id
FROM dbo.Posts p2
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 20000 ROWS FETCH NEXT 25 ROWS ONLY
)
SELECT p.*
FROM dbo.Posts p
JOIN c ON p.id = c.id;
Table 'Posts'. Scan count 1, logical reads 5914, physical reads 0, read-ahead reads 0, lob logical reads 11, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1453 ms
exec sp_executesql
N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;'
, N'@p0 nvarchar(250), @p1 int, @p2 int'
, @p0 = N'Data', @p1 = 20000, @p2 = 25;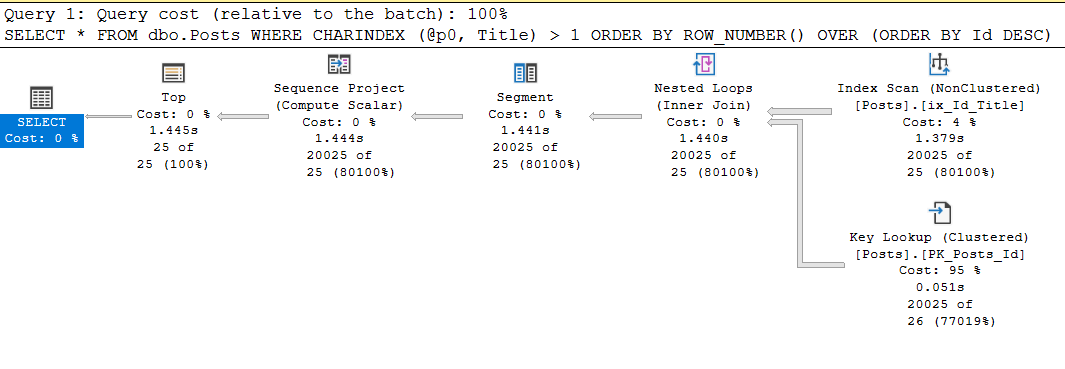
Table 'Posts'. Scan count 1, logical reads 87174, physical reads 0, read-ahead reads 0, lob logical reads 11, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1437 ms
Yes, the processor time is the same, since it is spent on charindex, but the request with the guide does an order of magnitude more reads, and this can become a problem.
Let me summarize the final result. Hints and guides can help you a lot in the here and now, but they can make it very easy to make things even worse. If you explicitly specify a hint with an index in the request text, and then delete the index, the query simply cannot be executed. On my SQL Server 2017, the query with the guide, after deleting the index, is executed fine - the guide is ignored, but I cannot be sure that it will always be this way and in all versions of SQL Server.
There is not much information about the plan guide in Russian, so I decided to write it myself. You can read hereabout limitations in using plan guides, in particular about the fact that sometimes an explicit indication of the index with a hint using PG can lead to the fact that requests will fall. I wish you never use them, and if you have to - well, good luck - you know where this can lead.