We bring to your attention a translation of an interesting research from the Crowdstrike company. The material is devoted to the use of the Rust language in the field of Data Science (in relation to malware analysis) and demonstrates how Rust can compete in such a field even with NumPy and SciPy, not to mention pure Python .

Enjoy reading!
Python is one of the most popular data science programming languages, and for good reason. The Python Package Index (PyPI) has a ton of impressive data science libraries such as NumPy, SciPy, Natural Language Toolkit, Pandas, and Matplotlib. With an abundance of high-quality analytics libraries available and an extensive developer community, Python is the obvious choice for many data scientists.
Many of these libraries are implemented in C and C ++ for performance reasons, but provide external function interfaces (FFIs) or Python bindings so that functions can be called from Python. These lower-level language implementations are intended to mitigate some of Python's most visible shortcomings, in particular in terms of execution time and memory consumption. If you can limit execution time and memory consumption, scalability is greatly simplified, which is critical for reducing costs. If we can write high-performance code that solves data science problems, then the integration of such code with Python will be a significant advantage.
When working at the intersection of data science and malware analysisnot only fast execution is required, but also efficient use of shared resources, again, for scaling. Scaling is one of the key issues in big data, such as efficiently handling millions of executables across multiple platforms. Achieving good performance on modern processors requires parallelism, usually implemented using multithreading; but it is also necessary to improve the efficiency of code execution and memory consumption. When solving such problems, it can be difficult to balance the resources of the local system, and it is even more difficult to correctly implement multi-threaded systems. The essence of C and C ++ is that thread safety is not provided. Yes, there are external platform-specific libraries, but ensuring thread safety is obviously a developer's duty.
Parsing malware is inherently dangerous. Malicious software often manipulates file format data structures in unintended ways, thus crippling analytics utilities. A relatively common pitfall that awaits us in Python is the lack of good type safety. Python, which generously accepts values
Nonewhen expected in their place bytearray, can slip into complete chaos, which can only be avoided by stuffing the code with checks for None. Such "duck typing" assumptions often lead to crashes.
But there is Rust. Rust is positioned in many ways as the ideal solution to all the potential problems outlined above: runtime and memory consumption are comparable to C and C ++, and extensive type safety is provided. Rust also provides additional amenities, such as strong memory safety guarantees and no runtime overhead. Since there is no such overhead, it makes it easier to integrate Rust code with code from other languages, in particular Python. In this article, we'll take a quick tour of Rust to see if it's worth the hype associated with it.
Sample Application for Data Science
Data science is a very broad subject area with many applied aspects, and it is impossible to discuss all of them in one article. A simple task for data science is to calculate informational entropy for byte sequences. A general formula for calculating entropy in bits is given on Wikipedia :
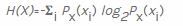
To calculate the entropy for a random variable
X, we first count how many times each possible byte value occurs 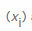 , and then divide that number by the total number of elements encountered to calculate the probability of encountering a specific value
, and then divide that number by the total number of elements encountered to calculate the probability of encountering a specific value 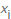 , respectively
, respectively 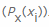 . Then we count the negative value from the weighted sum of the probabilities of a particular value xi occurring , as well as the so-called own information
. Then we count the negative value from the weighted sum of the probabilities of a particular value xi occurring , as well as the so-called own information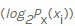 . Since we are calculating entropy in bits, it is used here
. Since we are calculating entropy in bits, it is used here 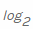 (note radix 2 for bits).
(note radix 2 for bits).
Let's give Rust a try and see how it handles entropy computation versus pure Python, as well as some of the popular Python libraries mentioned above. This is a simplified estimate of Rust's potential data science performance; this experiment is not a criticism of Python or the excellent libraries it contains. In these examples, we will generate our own C library from Rust code that we can import from Python. All tests were run on Ubuntu 18.04.
Pure Python
Let's start with a simple pure Python function (c
entropy.py) for calculating entropy bytearray, using only the math module from the standard library. This function is not optimized, so let's take it as a starting point for modifications and performance measurements.
import math
def compute_entropy_pure_python(data):
"""Compute entropy on bytearray `data`."""
counts = [0] * 256
entropy = 0.0
length = len(data)
for byte in data:
counts[byte] += 1
for count in counts:
if count != 0:
probability = float(count) / length
entropy -= probability * math.log(probability, 2)
return entropy
Python with NumPy and SciPy
Unsurprisingly, SciPy provides a function to calculate entropy. But first, we'll use a function
unique()from NumPy to calculate byte frequencies. Comparing the performance of the SciPy entropy function with other implementations is a bit unfair, since the SciPy implementation has additional functionality for calculating the relative entropy (Kullback-Leibler distance). Again, we're going to do a (hopefully not too slow) test drive to see what the performance of the compiled Rust libraries imported from Python will be. We'll stick with the SciPy implementation included in our script entropy.py.
import numpy as np
from scipy.stats import entropy as scipy_entropy
def compute_entropy_scipy_numpy(data):
""" bytearray `data` SciPy NumPy."""
counts = np.bincount(bytearray(data), minlength=256)
return scipy_entropy(counts, base=2)Python with Rust
Next, we'll explore our Rust implementation a little more, compared to previous implementations, for the sake of being solid and solid. Let's start with the default library package generated with Cargo. The following sections show how we modified the Rust package.
cargo new --lib rust_entropy
Cargo.tomlWe begin with a mandatory manifest file
Cargo.tomlthat defines Cargo package and specify a library name rust_entropy_lib. We use the public cpython container (v0.4.1) available from crates.io, in the Rust Package Registry. For this article, we are using Rust v1.42.0, the latest stable release available at the time of writing.
[package] name = "rust-entropy"
version = "0.1.0"
authors = ["Nobody <nobody@nowhere.com>"] edition = "2018"
[lib] name = "rust_entropy_lib"
crate-type = ["dylib"]
[dependencies.cpython] version = "0.4.1"
features = ["extension-module"]lib.rs
The implementation of the Rust library is pretty straightforward. As with our pure Python implementation, we initialize the counts array for every possible byte value and iterate over the data to populate the counts. To complete the operation, calculate and return the negative sum of probabilities multiplied by
probabilities.
use cpython::{py_fn, py_module_initializer, PyResult, Python};
///
fn compute_entropy_pure_rust(data: &[u8]) -> f64 {
let mut counts = [0; 256];
let mut entropy = 0_f64;
let length = data.len() as f64;
// collect byte counts
for &byte in data.iter() {
counts[usize::from(byte)] += 1;
}
//
for &count in counts.iter() {
if count != 0 {
let probability = f64::from(count) / length;
entropy -= probability * probability.log2();
}
}
entropy
}
All we are left with
lib.rsis a mechanism to call a pure Rust function from Python. We include in lib.rsa CPython-tuned (compute_entropy_cpython())function to call our “pure” Rust function (compute_entropy_pure_rust()). By doing this, we only benefit from maintaining a single pure Rust implementation and providing a CPython-friendly wrapper.
/// Rust CPython
fn compute_entropy_cpython(_: Python, data: &[u8]) -> PyResult<f64> {
let _gil = Python::acquire_gil();
let entropy = compute_entropy_pure_rust(data);
Ok(entropy)
}
// Python Rust CPython
py_module_initializer!(
librust_entropy_lib,
initlibrust_entropy_lib,
PyInit_rust_entropy_lib,
|py, m | {
m.add(py, "__doc__", "Entropy module implemented in Rust")?;
m.add(
py,
"compute_entropy_cpython",
py_fn!(py, compute_entropy_cpython(data: &[u8])
)
)?;
Ok(())
}
);Calling Rust Code from Python
Finally, we call the Rust implementation from Python (again, from
entropy.py). To do this, we first import our own dynamic system library compiled from Rust. Then, we simply call the provided library function that we previously specified when initializing the Python module using a macro py_module_initializer!in our Rust code. At this stage, we have only one Python ( entropy.py) module , which includes functions to call all implementations of entropy calculation.
import rust_entropy_lib
def compute_entropy_rust_from_python(data):
"" bytearray `data` Rust."""
return rust_entropy_lib.compute_entropy_cpython(data)We are building the above Rust library package on Ubuntu 18.04 using Cargo. (This link may come in handy for OS X users).
cargo build --releaseWhen finished with the assembly, we rename the resulting library and copy it to the directory where our Python modules are located, so that it can be imported from scripts. The library you created with Cargo is named
librust_entropy_lib.so, but you need to rename it to in rust_entropy_lib.soorder to be able to import successfully for these tests.
Performance check: results
We measured the performance of each function implementation using pytest breakpoints, calculating the entropy for over 1 million random bytes. All implementations are shown on the same data. The benchmarks (also included in entropy.py) are shown below.
# ### ###
# w/ NumPy
NUM = 1000000
VAL = np.random.randint(0, 256, size=(NUM, ), dtype=np.uint8)
def test_pure_python(benchmark):
""" Python."""
benchmark(compute_entropy_pure_python, VAL)
def test_python_scipy_numpy(benchmark):
""" Python SciPy."""
benchmark(compute_entropy_scipy_numpy, VAL)
def test_rust(benchmark):
""" Rust, Python."""
benchmark(compute_entropy_rust_from_python, VAL)Finally, we make separate simple driver scripts for each method needed to calculate the entropy. Next is a representative driver script for testing the pure Python implementation. The file contains
testdata.bin1,000,000 random bytes used to test all methods. Each method repeats the computation 100 times to make it easier to capture memory usage data.
import entropy
with open('testdata.bin', 'rb') as f:
DATA = f.read()
for _ in range(100):
entropy.compute_entropy_pure_python(DATA)Implementations for both SciPy / NumPy and Rust have shown good performance, easily beating an unoptimized pure Python implementation by more than 100 times. The Rust version performed only slightly better than the SciPy / NumPy version, but the results confirmed our expectations: pure Python is much slower than compiled languages, and extensions written in Rust can quite successfully compete with their C counterparts (beating them even in such microtesting).
There are also other methods of improving productivity. We could use modules
ctypesor cffi. You could add type hints and use Cython to generate a library that you could import from Python. All of these options require solution-specific trade-offs to be considered.

We also measured the memory usage for each feature implementation using the GNU application
time(not to be confused with the shell builtin command time). In particular, we measured the maximum resident set size.
Whereas in pure Python and Rust implementations the maximum sizes for this portion are quite similar, the SciPy / NumPy implementation consumes significantly more memory for this benchmark. This is presumably due to additional features loaded into memory during import. Be that as it may, calling Rust code from Python does not appear to introduce significant memory overhead.

Summary
We are extremely impressed with the performance we get when calling Rust from Python. In our frankly brief evaluation, the Rust implementation was able to compete in performance with the base C implementation from the SciPy and NumPy packages. Rust seems to be great for efficient large-scale processing.
Rust has shown not only excellent execution times; It should be noted that the memory overhead in these tests was also minimal. These runtime and memory usage characteristics appear to be ideal for scalability purposes. The performance of SciPy and NumPy C FFI implementations is definitely comparable, but with Rust we get additional advantages that C and C ++ do not give us. Memory safety and thread safety guarantees are a very attractive benefit.
While C provides comparable runtime to Rust, C itself does not provide thread safety. There are external libraries that provide this functionality for C, but it is the developer's responsibility to ensure that they are used correctly. Rust monitors for thread safety issues such as races at compile time - thanks to its ownership model - and the standard library provides a suite of concurrency mechanisms, including pipes, locks, and reference-counted smart pointers.
We are not advocating porting SciPy or NumPy to Rust, as these Python libraries are already well optimized and supported by cool developer communities. On the other hand, we strongly recommend porting code from pure Python to Rust that is not provided in high-performance libraries. In the context of data science applications used for security analysis, Rust appears to be a competitive alternative to Python, given its speed and security guarantees.