
Examining the sources in the repository allows you to assess the security level of applications. But if no one is looking at the code, problems will only grow. Fortunately, GitHub has its own security experts who recently discovered the Trojan in several Git repos. For some reason he was not noticed by the owners of these repositories. While we cannot dictate to other people how to manage our own repositories, we can learn from their mistakes. In this article we will look at useful techniques for working with repositories.
Explore your repository
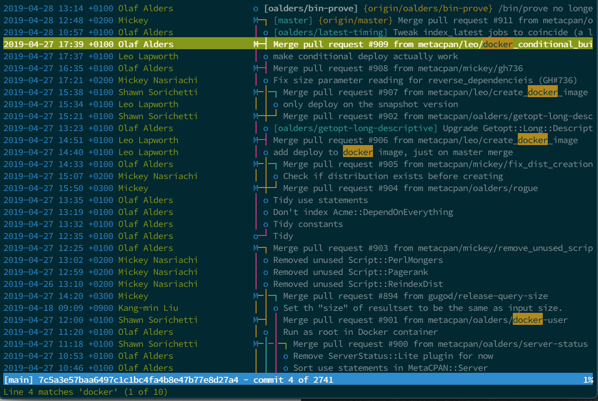
This is perhaps the most important recommendation. Whether you've created the repository yourself or handed it over to you, it's important to know the contents of your repository. At a minimum, you need to know the basic components of the codebase that you manage. If, after a few dozen merges, a random file appears, you can easily spot it because it will raise questions for you. Next, you will want to check it out to figure it out, and after that decide its fate.
Try not to add binaries
Git was originally designed for text files, be it C, Python or Java code, or JSON, YAML, XML, Markdown, HTML, and so on:
$ cat hello.txt
This is plain text.
It's readable by humans and machines alike.
Git knows how to version this.
$ git diff hello.txt
diff --git a/hello.txt b/hello.txt
index f227cc3..0d85b44 100644
--- a/hello.txt
+++ b/hello.txt
@@ -1,2 +1,3 @@
This is plain text.
+It's readable by humans and machines alike.
Git knows how to version this.Git doesn't like binaries:
$ git diff pixel.png
diff --git a/pixel.png b/pixel.png
index 563235a..7aab7bc 100644
Binary files a/pixel.png and b/pixel.png differ
$ cat pixel.png
PNG
▒
IHDR7n $gAMA
abKGD݊ tIME
-2R
IDA c` ! 3%tEXtdate:create2020-06-11T11:45:04+12:00 r.%tEXtdate:modify2020-06-11T11:45:0The data in a binary file cannot be parsed in the same way as plain text, so if something changes in the binary it must be completely overwritten.
To make matters worse, you cannot check (read and parse) the binary data yourself.
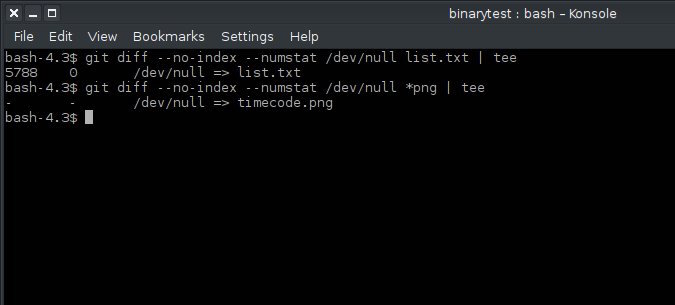
In addition to the usual POSIX tools, you can find binaries using git diff. When you try to run diff with the --numstat option, Git will return null:
$ git diff --numstat /dev/null pixel.png | tee
- - /dev/null => pixel.png
$ git diff --numstat /dev/null file.txt | tee
5788 0 /dev/null => list.txtIf you are considering adding binaries to your repository, stop and think. If a binary is generated during the build process, then why add it to your repo? If you do decide that it makes sense to do this, make sure you describe in a README file or similar place why you keep the binaries and what the protocol for updating them is. Updates should be done sparingly because every time you make a change to the blob, the storage space doubles.
Third party libraries must remain third party
While one of the many benefits of open source is that you can freely use and redistribute code that you did not write, there are many good reasons not to host a third-party library in your own repository. First of all, you will have to independently check all this code and its further updates to make sure that the library is reliable. Second, when you copy third party libraries into the Git repository, it shifts focus away from the main project.
Use Git Submodule to manage external dependencies .
Don't use git add blindly
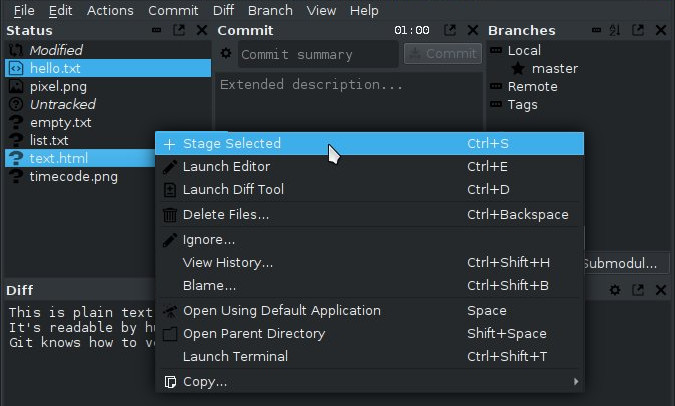
If your project compiled successfully, resist the urge to use the git add command. (where "." is the current directory for example). This is especially important if you are not manually compiling your project but using an IDE to manage your project. It can be extremely difficult to keep track of what has been added to your repository when the IDE manages your project. Therefore, it is important to add only what you yourself have created and prepared for adding, and not any new object that mysteriously appeared in your project folder.
So before running git add, review what will be added to the repository. If you see an unfamiliar object, find out where it came from and why it is still in your project directory after running make clean (or an equivalent command).
Use Git ignore
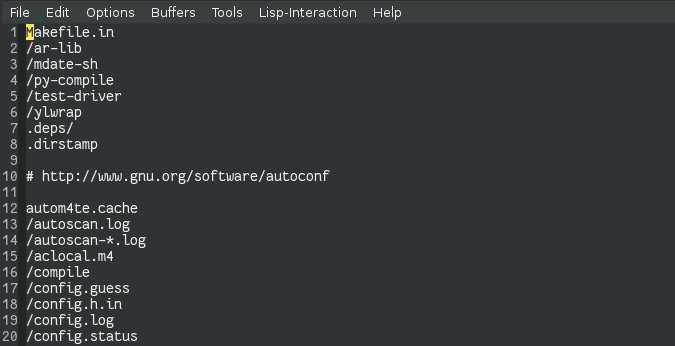
A typical project directory contains a lot of hidden files, metadata, and unnecessary artifacts. You are better off ignoring these objects: the more there are, the more likely you will be disturbed by this "garbage" and you will miss something important or dangerous.
The gitignore file makes it possible to filter out unnecessary things. Github.com/github/gitignore offers several custom gitignore templates that you can download and host in your project. Gitlab.com , for example, offered such templates several years ago.
Moderate codebase changes
When you receive a Pull or Pull Request, or when you receive a patch by email, you should make sure everything is fine. Your job is to study the new code coming into your codebase and understand what it does. If you disagree with its implementation, or worse, do not understand this implementation, write a message to the sender and ask for clarification. There is nothing wrong with learning new code that claims a place in your project. Moreover, you do it for the benefit of your users: in this case, they will clearly understand what changes you are accepting and why.
Take responsibility
Keeping open source software secure is a community job. Explore the codebase, discourage clutter and ignore potential security threats in repositories you clone. Git is powerful, but it's just a computer program, so the responsibility for managing the repos is ultimately yours.
Advertising
Epic Servers are Linux or Windows virtual servers with powerful AMD EPYC processors and very fast Intel NVMe drives. Disperse like hot cakes!
