
Of course, NSPK is not a startup, but such an atmosphere prevailed in the company in the first years of its existence, and these were very interesting years. My name is Dmitry Kornyakov , I have been supporting Linux infrastructure with high availability requirements for over 10 years. He joined the NSPK team in January 2016 and, unfortunately, did not see the very beginning of the company's existence, but came at the stage of great changes.
In general, we can say that our team supplies 2 products for the company. The first is infrastructure. Mail should go, DNS should work, and domain controllers should let you on servers that should not fall. The IT landscape of the company is huge! These are business & mission critical systems, the availability requirements for some are 99,999. The second product is the servers themselves, physical and virtual. The existing ones need to be monitored, and new ones are regularly supplied to customers from many departments. In this article, I want to focus on how we developed the infrastructure that is responsible for the life cycle of servers.
The beginning of the path
At the beginning of the path, our technology stack looked like this:
OS CentOS 7
Domain controllers FreeIPA
Automation - Ansible (+ Tower), Cobbler
All of this was located in 3 domains, spread over several data centers. In one data center - office systems and test sites, in the rest PROD.
At some point, the creation of servers looked like this:
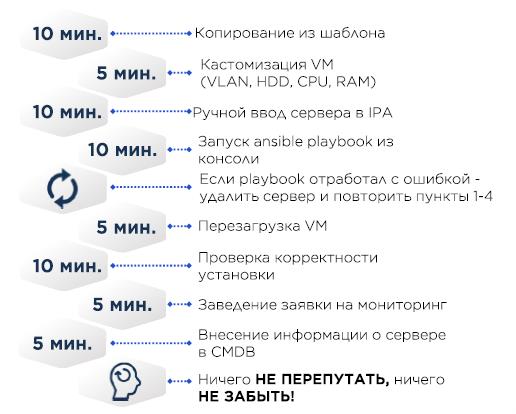
In the VM CentOS minimal template and the required minimum, like the correct /etc/resolv.conf, the rest comes through Ansible.
CMDB - Excel.
If the server is physical, then instead of copying the virtual machine, the OS was installed on it using Cobbler - the MAC addresses of the target server are added to the Cobbler config, the server receives an IP address via DHCP, and then the OS is poured.
At first, we even tried to do some kind of configuration management in Cobbler. But over time, this began to bring problems with the portability of configurations both to other data centers and to Ansible code for preparing the VM.
At that time, many of us perceived Ansible as a convenient extension of Bash and did not skimp on constructions using the shell, sed. In general Bashsible. This ultimately led to the fact that if the playbook for some reason did not work on the server, it was easier to delete the server, fix the playbook and re-run. In fact, there was no script versioning, configuration portability, too.
For example, we wanted to change some config on all servers:
- We change the configuration on existing servers in the logical segment / data center. Sometimes not overnight - availability requirements and the law of large numbers do not allow all changes to be applied at once. And some changes are potentially destructive and require restarting anything - from services to the OS itself.
- Fixing in Ansible
- Fixing in Cobbler
- Repeat N times for each logical segment / data center
In order for all changes to take place smoothly, many factors had to be taken into account, and changes are constantly occurring.
- Refactoring ansible code, config files
- Changing internal best practice
- Changes following the analysis of incidents / accidents
- Changing security standards, both internal and external. For example, PCI DSS is updated with new requirements every year
Infrastructure growth and the beginning of the path The
number of servers / logical domains / data centers grew, and with them the number of errors in configurations. At some point, we came to three directions, towards which we need to develop configuration management:
- Automation. As far as possible, the human factor in repetitive operations should be avoided.
- . , . . – , .
- configuration management.
It remains to add a couple of tools.
We chose GitLab CE as our code repository, not least for the built-in CI / CD modules.
Vault of secrets - Hashicorp Vault, incl. for the great API.
Testing configurations and ansible roles - Molecule + Testinfra. Tests run much faster if connected to ansible mitogen. In parallel, we began to write our own CMDB and an orchestrator for automatic deployment (in the picture above Cobbler), but this is a completely different story, which my colleague and the main developer of these systems will tell in the future.
Our pick:
Molecule + Testinfra
Ansible + Tower + AWX Server
World + DITNET (In-house)
Cobbler
Gitlab + GitLab runner
Hashicorp Vault

Speaking of ansible roles. At first it was alone, after several refactorings there are 17 of them. I strongly recommend breaking the monolith into idempotent roles, which can then be run separately, you can additionally add tags. We divided the roles by functionality - network, logging, packages, hardware, molecule etc. In general, we adhered to the strategy below. I do not insist that this is the only truth, but it worked for us.
- Copying servers from the "golden image" is evil!
The main disadvantage is that you do not know exactly what state the images are in now, and that all changes will come to all images in all virtualization farms. - Use the default configuration files to a minimum and agree with other departments about the core system files you are responsible for, for example:
- /etc/sysctl.conf , /etc/sysctl.d/. , .
- override systemd .
- , sed
- :
- ! Ansible-lint, yaml-lint, etc
- ! bashsible.
- Ansible molecule .
- , ( 100) 70000 . .

Our implementation
So, the ansible roles were ready, templated and checked by linters. And even gits are raised everywhere. But the question of reliable delivery of code to different segments remained open. We decided to synchronize with scripts. It looks like this:

After the change has arrived, CI is launched, a test server is created, roles are rolled, tested with a molecule. If everything is ok, the code goes to the production branch. But we are not applying the new code to the existing servers in the machine. This is a kind of stopper that is necessary for the high availability of our systems. And when the infrastructure becomes huge, the law of large numbers comes into play - even if you are sure that the change is harmless, it can lead to sad consequences.
There are also many options for creating servers. We ended up choosing custom python scripts. And for CI ansible:
- name: create1.yml - Create a VM from a template
vmware_guest:
hostname: "{{datacenter}}".domain.ru
username: "{{ username_vc }}"
password: "{{ password_vc }}"
validate_certs: no
cluster: "{{cluster}}"
datacenter: "{{datacenter}}"
name: "{{ name }}"
state: poweredon
folder: "/{{folder}}"
template: "{{template}}"
customization:
hostname: "{{ name }}"
domain: domain.ru
dns_servers:
- "{{ ipa1_dns }}"
- "{{ ipa2_dns }}"
networks:
- name: "{{ network }}"
type: static
ip: "{{ip}}"
netmask: "{{netmask}}"
gateway: "{{gateway}}"
wake_on_lan: True
start_connected: True
allow_guest_control: True
wait_for_ip_address: yes
disk:
- size_gb: 1
type: thin
datastore: "{{datastore}}"
- size_gb: 20
type: thin
datastore: "{{datastore}}"This is what we have come to, the system continues to live and develop.
- 17 ansible roles for configuring the server. Each of the roles is designed to solve a separate logical task (logging, auditing, user authorization, monitoring, etc.).
- Role testing. Molecule + TestInfra.
- Own development: CMDB + Orchestrator.
- Server creation time ~ 30 minutes, automated and practically independent of the task queue.
- The same state / naming of infrastructure in all segments - playbooks, repositories, virtualization elements.
- Daily check of the status of servers with generation of reports on discrepancies with the standard.
I hope my story will be useful to those who are at the beginning of the journey. What automation stack are you using?