 Dialogue 2020 , an international scientific conference on computational linguistics and intelligent technology, has recently ended . For the first time, the Phystech School of Applied Mathematics and Informatics (FPMI) of MIPT became a partner of the conference . Traditionally, one of the key events of the Dialogue is Dialogue Evaluation , a competition between the developers of automatic systems for linguistic text analysis. We have already talked on Habré about the tasks that the participants of the competition solved last year, for example, about generating headings and finding missing words in the text... Today we talked with the winners of two tracks of this year's Dialogue Evaluation - Vladislav Korzun and Daniil Anastasyev - about why they decided to participate in technology competitions, what problems and in what ways they solved, what the guys are interested in, where they studied and what they plan to do in the future. Welcome to the cat!
Dialogue 2020 , an international scientific conference on computational linguistics and intelligent technology, has recently ended . For the first time, the Phystech School of Applied Mathematics and Informatics (FPMI) of MIPT became a partner of the conference . Traditionally, one of the key events of the Dialogue is Dialogue Evaluation , a competition between the developers of automatic systems for linguistic text analysis. We have already talked on Habré about the tasks that the participants of the competition solved last year, for example, about generating headings and finding missing words in the text... Today we talked with the winners of two tracks of this year's Dialogue Evaluation - Vladislav Korzun and Daniil Anastasyev - about why they decided to participate in technology competitions, what problems and in what ways they solved, what the guys are interested in, where they studied and what they plan to do in the future. Welcome to the cat!
Vladislav Korzun, winner of the Dialogue Evaluation RuREBus-2020 track

What do you do?
I am a developer at NLP Advanced Research Group at ABBYY. We are currently solving a one shot learning task for extracting entities. That is, having a small training sample (5-10 documents), you need to learn how to extract specific entities from similar documents. For this, we are going to use the outputs of the NER model trained on standard entity types (Person, Location, Organization) as features for solving this problem. We also plan to use a special language model, which was trained on documents similar in subject matter to our task.
What tasks did you solve at Dialogue Evaluation?
At the Dialogue, I took part in the RuREBus competition dedicated to extracting entities and relationships from specific documents of the corpus of the Ministry of Economic Development. This case was very different from the cases used, for example, in the Conll competition . First, the types of entities themselves were not standard (Persons, Locations, Organizations), among them there were even unnamed and substantive actions. Secondly, the texts themselves were not sets of verified sentences, but real documents, which led to various lists, headings, and even tables. As a result, the main difficulties arose precisely with data processing, and not with solving the problem. in fact, these are classic Named Entity Recognition and Relation Extraction tasks.
In the competition itself, there were 3 tracks: NER, RE with given entities, and end-to-end RE. I tried to solve the first two. In the first task, I used classical approaches. First, I tried to use a recurrent network as a model, and fasttext word embeddings, capitalization patterns, symbolic embeddings and POS tags as features [1]. Then I have already used various pretrained BERTs [2], which are quite superior to my previous approach. However, this was not enough to take first place in this track.
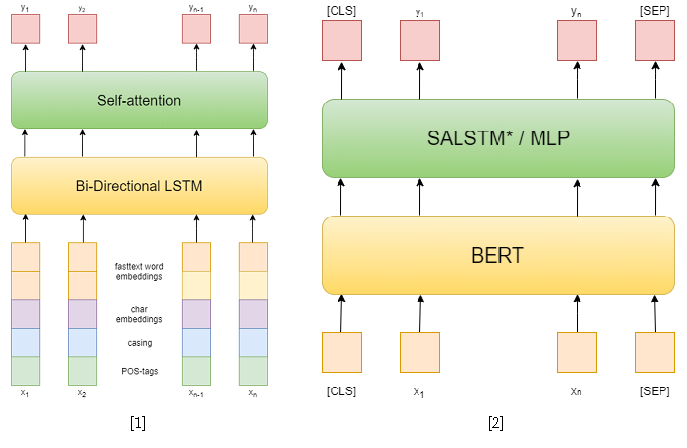
But in the second track I succeeded. To solve the problem of extracting relations, I reduced it to the problem of classifying relations, similar to SemEval 2010 Task 8 . In this problem, for each sentence, one pair of entities is given, for which the relationship needs to be classified. And in a track, each sentence can contain as many entities as you want, however, it simply reduces to the previous one by sampling the sentence for each pair of entities. Also, during training, I took negative examples at random for each sentence in a size not exceeding twice the number of positive ones in order to reduce the training sample.
As approaches to solving the problem of classifying relations, I used two models based on BERT-e. In the first one, I simply concatenated BERT outputs with NER embeddings and then averaged the features for each token using Self-attention [3]. One of the best solutions for SemEval 2010 Task 8 - R-BERT [4] was taken as the second model. The essence of this approach is as follows: insert special tokens before and after each entity, average the BERT outputs for each entity's tokens, combine the resulting vectors with the output corresponding to the CLS token, and classify the resulting feature vector. As a result, this model took first place in the track. The results of the competition are available here .
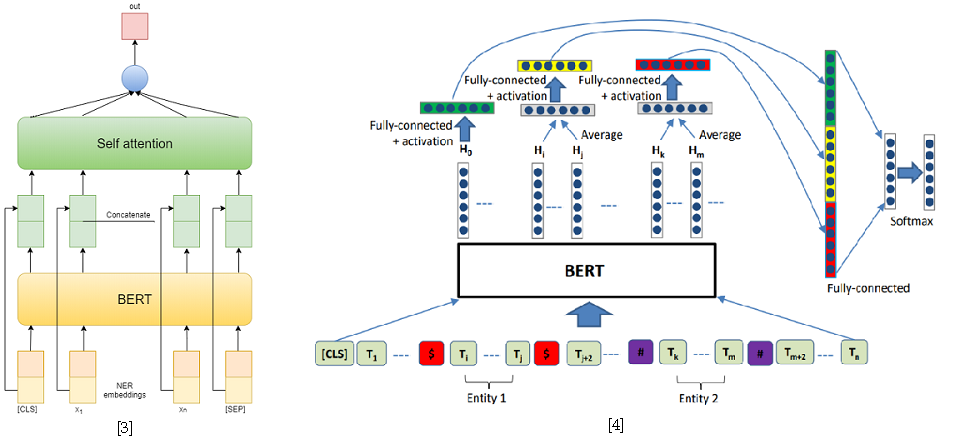
[4] Wu, S., He, Y. (2019, November). Enriching pre-trained language model with entity information for relation classification. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management ( pp. 2361-2364 ).
What seemed to you the most difficult in these tasks?
The most problematic was the processing of the case. The tasks themselves are as classic as possible, for their solution there are already ready-made frameworks, for example, AllenNLP. But the answer needs to be given with saving token spans, so I couldn't just use the ready-made pipeline without writing a lot of additional code. Therefore, I decided to write the entire pipeline in pure PyTorch so as not to miss anything. Although I still used some modules from AllenNLP.
There were also many rather long sentences in the corpus, which caused inconvenience when teaching large transformers, for example, BERT, because they become demanding on video memory with increasing sentence length. However, most of these sentences are semicolon-delimited enumerations and could be separated by that character. I simply divided the remaining offers by the maximum number of tokens.
Have you participated in Dialogue and tracks before?
Last year I spoke with my master's degree at the student session.
Why did you decide to participate in the competition this year?
At this time, I was just solving the problem of extracting relations, but for a different corps. I tried to use a different approach based on parse trees. The path in the tree from one entity to another was used as input. But this approach, unfortunately, did not show strong results, although it was on a level with the approach based on recurrent networks, using token embeddings and other features as signs, such as the length of the path from a token to a root or one of the entities in the syntactic tree. parsing, as well as the relative position of the entities.
In this competition, I decided to participate, because I already had some groundwork for solving similar problems. And why not apply them in a competition and get published? It turned out not as easy as I thought, but it is rather due to problems with interaction with the hulls. As a result, for me it was more an engineering task than a research one.
Have you participated in other competitions?
At the same time, our team participated in SemEval . Ilya Dimov was mainly involved in the task, I just suggested a couple of ideas. There was the task of classifying propaganda: the span of the text was selected and it was necessary to classify it. I suggested using the R-BERT approach, that is, to select this entity in tokens, insert a special token in front of it and after it, and average the outputs. As a result, this gave a small increase. This is the scientific value: to solve the problem, we used a model designed for something completely different.
I also took part in ABBYY hackathon, in ACM icpc - competition in sports programming in the first years. We didn't get very far back then, but it was fun. Such competitions are very different from those presented at the Dialogue, where there is enough time to calmly implement and test several approaches. In hackathons, you need to do everything quickly, there is no time to relax, there is no tea. But this is the beauty of such events - they have a specific atmosphere.
What are the most interesting problems you solved at competitions or at work?
There is a GENEA gesture generation competition coming up soon and I'm going to go there. I think it will be interesting. This is a workshop at ACM - International Conference on Intelligent Virtual Agents . In this competition, it is proposed to generate gestures for a 3D human model based on voice. I spoke this year at the Dialogue with a similar topic, made a small overview of approaches to the problem of automatic generation of facial expressions and gestures from voice. I need to gain experience, because I still have to defend my dissertation on a similar topic. I want to try to create a reading virtual agent, with facial expressions, gestures, and of course, voice. Current approaches to speech synthesis allow to generate fairly realistic speech from text, while gesture generation approaches allow to generate gestures from voice. So why not combine these approaches.
By the way, where are you studying now?
I am a postgraduate student at the Department of Computational Linguistics at ABBYY at the Phystech School of Applied Mathematics and Informatics at MIPT . I will defend my thesis in two years.
What knowledge and skills acquired at the university help you now?
Oddly enough, mathematics. Even though I don't integrate every day and do not multiply matrices in my head, mathematics teaches analytical thinking and the ability to figure out anything. After all, any exam includes proving theorems, and trying to learn them is useless, but understanding and proving yourself, remembering only an idea, is possible. We also had good programming courses, where we learned from a low level to understand how everything works, analyzed various algorithms and data structures. And now it won't be a problem to deal with a new framework or even a programming language. Yes, of course, we had courses in machine learning, and in NLP, in particular, but still, it seems to me that basic skills are more important.
Daniil Anastasyev, winner of the Dialogue Evaluation GramEval-2020 track

What do you do?
I am developing the voice assistant "Alice", I work in the search for meaning group. We analyze the requests that come to Alice. A standard example of a query is "What is the weather in Moscow tomorrow?" You need to understand that this is a request about the weather, that the request asks about the location (Moscow) and there is an indication of the time (tomorrow).
Tell us about the problem you solved this year on one of the Dialogue Evaluation tracks.
I was doing a task very close to what ABBYY is doing. It was necessary to build a model that would analyze the sentence, make morphological and syntactic analysis, and define lemmas. This is very similar to what they do in school. It took me about 5 days off to build the model.

The model studied in normal Russian, but, as you can see, it also works in the language that was in the problem.
Does this sound like what you do at work?
Probably not. Here you need to understand that this task in itself does not carry much meaning - it is solved as a subtask within the framework of solving some important business problem. So, for example, in ABBYY, where I once worked, morpho-syntactic analysis is the initial stage in solving the problem of information extraction. Within the framework of my current tasks, I do not need such analyzes. However, the additional experience of working with pretrained language models such as BERT feels like it is certainly useful for my work. In general, this was the main motivation for participation - I did not want to win, but to practice and gain some useful skills. In addition, my diploma was partly related to the topic of the problem.
Have you participated in Dialogue Evaluation before?
Participated in the MorphoRuEval-2017 track on the 5th year and also then took 1st place. Then it was necessary to define only morphology and lemmas, without syntactic relations.
Is it realistic to apply your model to other tasks right now?
Yes, my model can be used for other tasks - I have posted all the source code. I plan to post the code using a lighter and faster but less accurate model. In theory, if anyone wants to, the current model can be used. The problem is that it will be too big and slow for most. In competition, no one cares about speed, it is interesting to achieve the highest possible quality, but in practical application, everything is usually the other way around. Therefore, the main benefit of such large models is knowing what quality is the most achievable in order to understand what you are sacrificing.
Why do you participate in Dialogue Evaluation and other similar competitions?
Hackathons and such competitions are not directly related to my work, but it is still a rewarding experience. For example, when I participated in the AI Journey hackathon last year, I learned some things that I then used in my work. The task was to learn how to pass the exam in the Russian language, that is, to solve tests and write an essay. It is clear that all this has little to do with work. But the ability to quickly come up with and train a model that solves some problem is very useful. By the way, my team and I won first place.
What education did you get and what did you do after university?
He graduated from the Bachelor's and Master's degrees of the Department of Computational Linguistics ABBYY at the Moscow Institute of Physics and Technology, graduated in 2018. He also studied at the School of Data Analysis (SHAD). When it came time to choose a basic department in the 2nd year, most of the group went to the departments of ABBYY - computational linguistics or image recognition and text processing. In the undergraduate program we were taught to program well - there were very useful courses. From the 4th year I worked at ABBYY for 2.5 years. First, in the morphology group, then I was engaged in tasks related to language models to improve text recognition in ABBYY FineReader. I wrote code, trained models, now I'm doing the same, but for a completely different product.
How do you spend your free time?
I love reading books. Depending on the season, I try to run or ski. I am fond of photography while traveling.
Do you have plans or goals for the next, say, 5 years?
5 years is too far planning horizon. I don't even have 5 years of work experience. Over the past 5 years, a lot has changed, now there is clearly a different feeling from life. I can hardly imagine what else can change, but there are thoughts of getting a PhD abroad.
What advice can you give to young developers who are engaged in computational linguistics and are at the beginning of their journey?
It is best to practice, try and compete. Complete beginners can take one of the many courses: for example, from SHAD , DeepPavlov, or even my own, which I once taught at ABBYY.
, ABBYY : () (). 15 brains@abbyy.com , , GPA 5- 10- .
, ABBYY – .