
In the first part, I talked about what simulators are in general, as well as about simulation levels. Now, based on that knowledge, I propose to dive a little deeper and talk about full-platform simulation, how to assemble tracks, what to do with them later, as well as cycle-by-cycle microarchitectural emulation.
Full platform simulator, or “Alone in the field - not a warrior”
If you need to investigate the operation of one specific device, for example, a network card, or write a firmware or driver for this device, then such a device can be modeled separately. However, using it in isolation from the rest of the infrastructure is not very convenient. To run the corresponding driver, you need a central processor, memory, access to the bus for data transfer, and so on. In addition, the driver needs an operating system (OS) and network stack. In addition to this, a separate packet generator and response server may be required.
The full platform simulator creates an environment for running a full software stack, which includes everything from the BIOS and the bootloader to the OS itself and its various subsystems, such as the same network stack, drivers, and user-level applications. To do this, it implements software models of most computer devices: processor and memory, disk, input-output devices (keyboard, mouse, display), as well as the same network card.
Below is a block diagram of the x58 chipset from Intel. In a full-platform computer simulator on this chipset, it is necessary to implement most of the listed devices, including those located inside the IOH (Input / Output Hub) and ICH (Input / Output Controller Hub), which are not drawn in detail on the block diagram. Although, as practice shows, there are not so few devices that are not used by the software that we are going to run. Models of such devices need not be created.

Most often, full platform simulators are implemented at the processor instruction level (ISA, see previous article). This allows you to create the simulator itself relatively quickly and inexpensively. The ISA level is also good in that it remains more or less constant, unlike, for example, the API / ABI level, which changes more often. In addition, the implementation at the instruction level allows you to run the so-called unmodified binary software, that is, run the already compiled code without any changes, exactly as it is used on real hardware. In other words, you can make a copy (“dump”) of the hard drive, specify it as the image for the model in a full-platform simulator, and voila! - OS and other programs are loaded in the simulator without any additional actions.
Simulator Performance

As mentioned just above, the very process of simulating the entire system as a whole, that is, all its devices, is a rather slow exercise. If you also implement all this at a very detailed level, for example, microarchitectural or logical, then the execution will become extremely slow. But the level of instructions is a suitable choice and allows the OS and programs to run at speeds sufficient for the user to comfortably interact with them.
Here it will just be appropriate to touch on the topic of simulator performance. It is usually measured in IPS (instructions per second), more precisely in MIPS (millions IPS), that is, the number of processor instructions executed by the simulator per second. At the same time, the simulation speed also depends on the performance of the system on which the simulation itself is running. Therefore, it may be more correct to speak of a “slowdown” of the simulator compared to the original system.
The most common full-platform simulators on the market, the same QEMU, VirtualBox or VmWare Workstation, have good performance. It may not even be noticeable to the user that the work is going on in the simulator. This is due to the special virtualization feature implemented in the processors, binary translation algorithms, and other interesting things. This is all a topic for a separate article, but in short, virtualization is a hardware feature of modern processors, which allows simulators not to simulate instructions, but to send them for execution directly to a real processor, if, of course, the architectures of the simulator and the processor are similar. Binary translation is the translation of the guest machine code into the host code and subsequent execution on a real processor. As a result, the simulation is only slightly slower, every 5-10 times,and often generally works at the same speed as the real system. Although this is influenced by a lot of factors. For example, if we want to simulate a system with several tens of processors, then the speed will immediately drop several tens of times. On the other hand, simulators like Simics in the latest versions support multiprocessor host hardware and effectively parallelize simulated kernels to the kernels of a real processor.in recent versions, simulators like Simics support multiprocessor host hardware and effectively parallelize simulated cores to cores of a real processor.simulators like Simics in the latest versions support multiprocessor host hardware and effectively parallelize simulated cores to real processor cores.
If we talk about the speed of microarchitectural simulation, then it is usually several orders of magnitude, about 1000-10000 times, slower than execution on a regular computer, without simulation. And implementations at the level of logical elements are slower by several orders of magnitude. Therefore, FPGA is used as an emulator at this level, which can significantly increase performance.
The graph below shows the approximate dependence of simulation speed on model detail.
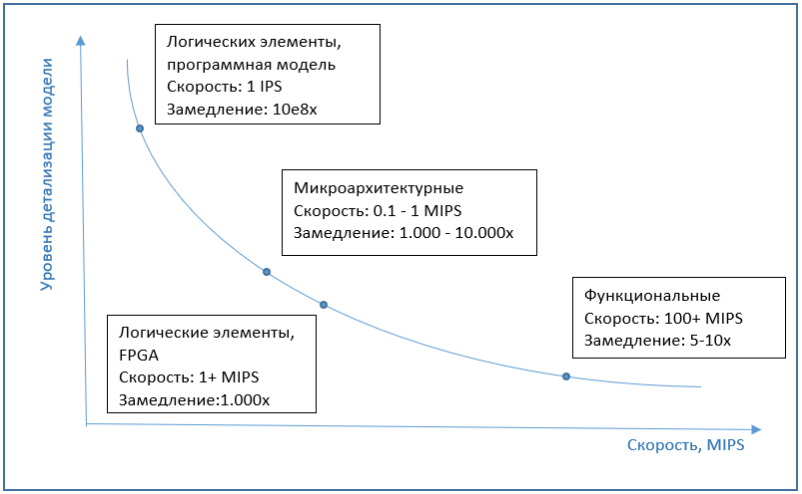
Bottom-line simulation
Despite the low execution speed, microarchitectural simulators are quite common. The simulation of the internal blocks of the processor is necessary in order to accurately simulate the execution time of each instruction. A misunderstanding may arise here - after all, it would seem, why not just take and program the execution time for each instruction. But such a simulator will work very inaccurately, since the execution time of the same instruction may differ from call to call.
The simplest example is a memory access instruction. If the requested memory location is available in the cache, then the execution time will be minimal. If there is no such information in the cache ("cache miss", cache miss), then this will greatly increase the execution time of the instruction. Thus, a cache model is needed for accurate simulation. However, the cache model is not limited to this. The processor will not just wait for data to be received from memory if it is not in the cache. Instead, it will start executing the next instructions, choosing those that do not depend on the result of reading from memory. This is the so-called “out of order execution” (OOO, out of order execution), necessary to minimize processor downtime. Simulation of the corresponding processor blocks will help to take all this into account when calculating the execution time of instructions. Among these instructions being executed,while waiting for the result of reading from memory, a conditional branch operation may occur. If the result of fulfilling the condition is unknown at the moment, then again the processor does not stop the execution, but makes an “assumption”, performs the corresponding transition and continues to preemptively execute instructions from the place of transition. Such a block, called a branch predictor, must also be implemented in the microarchitectural simulator.
The picture below shows the main blocks of the processor, it is not necessary to know it, it is given only to show the complexity of the microarchitectural implementation.
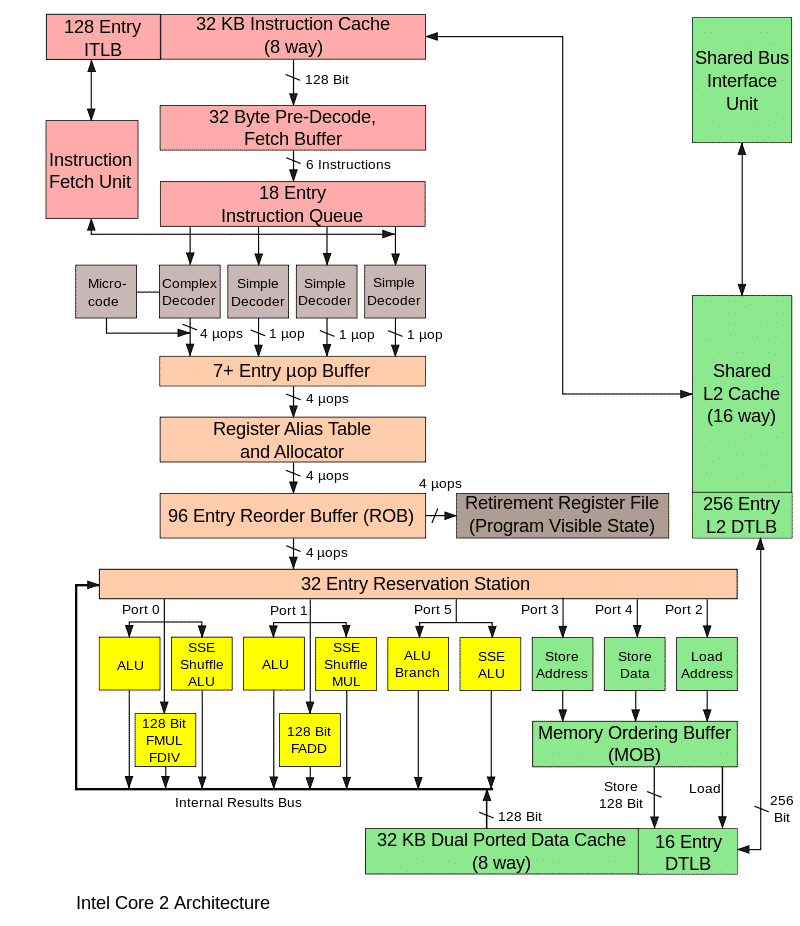
The operation of all these blocks in a real processor is synchronized with special clock signals, and the same happens in the model. This microarchitectural simulator is called cycle accurate. Its main purpose is to accurately predict the performance of the processor being developed and / or calculate the execution time of a certain program, for example, a benchmark. If the values are lower than necessary, then you will need to refine the algorithms and processor units or optimize the program.
As shown above, tick-wise simulation is very slow, so it is used only when studying certain moments of the program, where you need to find out the real speed of the programs and evaluate the future performance of the device, the prototype of which is being modeled.
At the same time, a functional simulator is used to simulate the rest of the program’s time. How does this combined use actually occur? First, a functional simulator is launched, on which the OS and everything necessary to run the program under study are loaded. After all, we are not interested in either the OS itself, or the initial stages of launching the program, its configuration, and so on. However, we also cannot skip these parts and go straight to the execution of the program from the middle. Therefore, all these preliminary steps are run on a functional simulator. After the program is executed until the moment of interest to us, there are two options. You can replace the model with a push-pull model and continue execution. Simulation mode, in which executable code is used (i.e. regular compiled program files),called execution driven simulation. This is the most common simulation option. Another approach is also possible - trace driven simulation.
Trace based simulation
It has two steps. Using a functional simulator or on a real system, a log of program actions is collected and written to a file. Such a log is called a trace. Depending on what is being investigated, the route may include executable instructions, memory addresses, port numbers, information about interrupts.
The next step is to "play" the trace, when the cycle-by-clock simulator reads the trace and executes all the instructions written in it. At the end, we get the execution time of a given piece of program, as well as various characteristics of this process, for example, the percentage of cache hits.
An important feature of working with traces is determinism, that is, starting the simulation in the manner described above, over and over again we reproduce the same sequence of actions. This makes it possible, by changing the parameters of the model (the size of the cache, buffers and queues) and using different internal algorithms or tuning them, to investigate how a particular parameter affects the system performance and which option gives the best results. All this can be done with the prototype model of the device before creating a real hardware prototype.
The complexity of this approach lies in the need to pre-run the application and collect the trace, as well as the huge file size with the trace. The pluses include the fact that it is enough to simulate only the part of the device or platform that is of interest, while the simulation of execution requires, as a rule, a complete model.
So, in this article we examined the features of full-platform simulation, talked about the speed of implementations at different levels, beat simulation and traces. In the next article, I will describe the main scenarios for using simulators, both for personal purposes and in terms of development in large companies.