
-, , .
, , . – , , – .
, ,
All the physical effects listed in the previous articles ( one , two , three ) are important to understand not just in order to know how the world works. Most likely they will have to be taken into account when building a model that can correctly predict the future. Why should we be able to predict the future in oil production if the price of oil and the coronavirus still cannot be predicted? And then, why and everywhere: to make the right decisions.

In the case of the field, we cannot directly observe what is happening underground between the wells. Almost everything that is available to us is tied to wells, that is, to rare points in the vast expanses of swamps (everything that we can measure is contained in about 0.5% of the rock, we can only “guess” about the properties of the remaining 99.5%). These are measurements taken on wells when the well was being built. These are the readings of the instruments that are installed on the wells (bottomhole pressure, the proportion of oil, water and gas in the product). And these are the measured and set parameters of the wells - when to turn on, when to turn off, at what speed to pump.
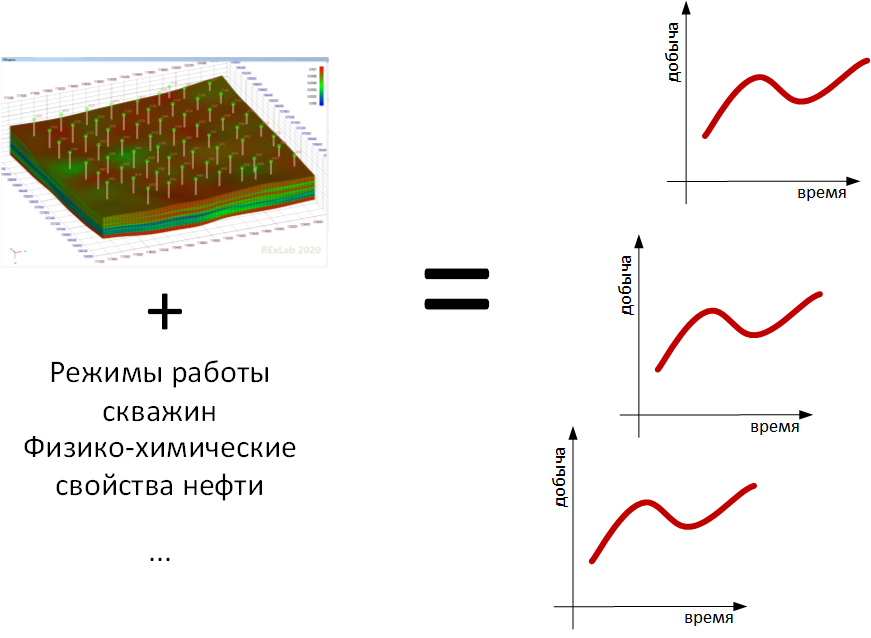
A correct model is a model that predicts the future correctly. But since the future has not come yet, and I want to understand whether the model is good now, then they do this: they put all the available factual information about the field into the model, in accordance with the assumptions they add their guesses about unknown information (the catch phrase “two geologists - three opinions ”just about these guesses) and simulate the processes of filtration, pressure redistribution and so on that took place underground. The model gives out which well performance indicators should have been observed, and they are compared with the actual observed indicators. In other words, we are trying to build a model that reproduces history.
Actually, you can cheat and simply require the model to produce the data you need. But, firstly, this cannot be done, and secondly, they will still notice (experts in the very state bodies where the model needs to be submitted).
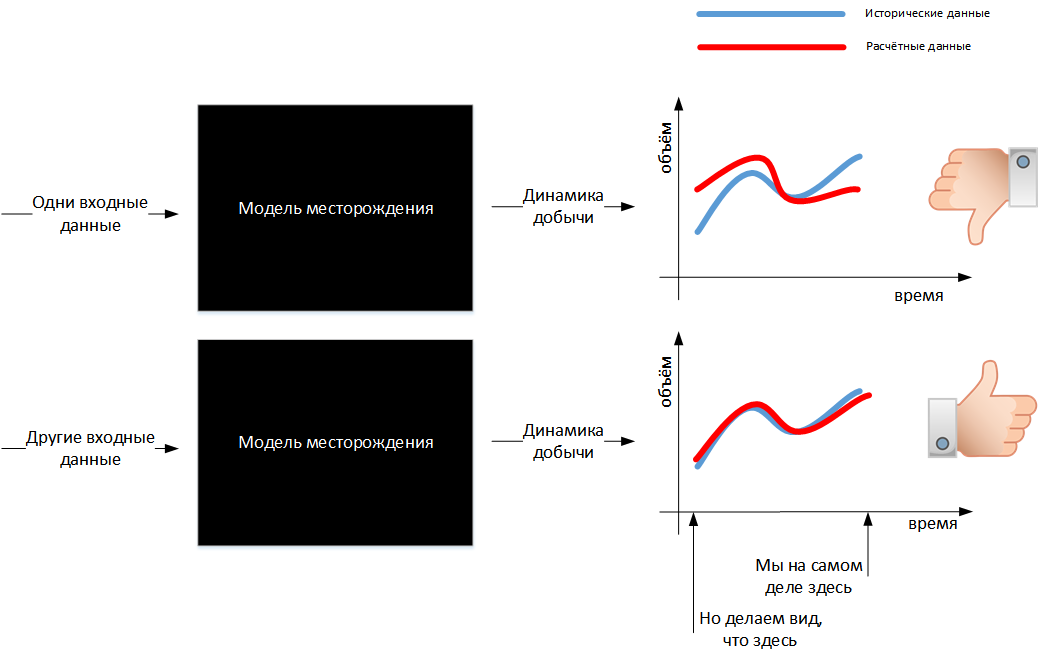
If the model cannot reproduce the story, it is necessary to change its input, but what? Actual data cannot be changed: this is the result of observation and measurement of reality - data from devices. Devices, of course, have their own error, and devices are used by people who can also screw up and lie, but the uncertainty of the actual data in the model is usually small. It is possible and necessary to change what has the greatest uncertainty: our assumptions about what is happening between the wells. In this sense, building a model is an attempt to reduce the uncertainty in our knowledge of reality (in mathematics, this process is known as solving an inverse problem, and inverse problems in our area - like bicycles in Beijing!).
If the model reproduces history correctly enough, we have the hope that our knowledge of reality, embedded in the model, does not differ much from this very reality. Then and only then can we launch such a model for a forecast, into the future, and we will have more reason to believe such a forecast.
What if you managed to make not one, but several different models, which all reproduce history quite well, but at the same time give different predictions? We have no choice but to live with this uncertainty, to make decisions with it in mind. Moreover, having several models giving a range of possible forecasts, we can try to quantify the risks of making a decision, while having one model, we will be in unjustified confidence that everything will be as the model predicts.
Models in the life of the field
In order to make decisions during field development, a holistic model of the entire field is needed. Moreover, today it is impossible to develop a field without such a model: such a model is required by the state bodies of the Russian Federation.

It all starts with a seismic model, which is created from the results of a seismic survey. Such a model allows one to “see” three-dimensional surfaces underground - specific layers from which seismic waves are well reflected. It gives almost no information about the properties we need (porosity, permeability, saturation, etc.), but it shows how some layers bend in space. If you made a multilayer sandwich, and then somehow bent it (well, or someone sat on it), then you have every reason to believe that all layers bent about the same. Therefore, we can understand how the layer cake of various sediments attacking the ocean floor bent, even if we see only one of the layers on the seismic model, which, by a lucky chance, reflects well seismic waves. At this point, data science engineers revived,because the automatic selection of such reflective horizons in a cube, which is what the participants of one of ourhackathons , - the classic task of pattern recognition.
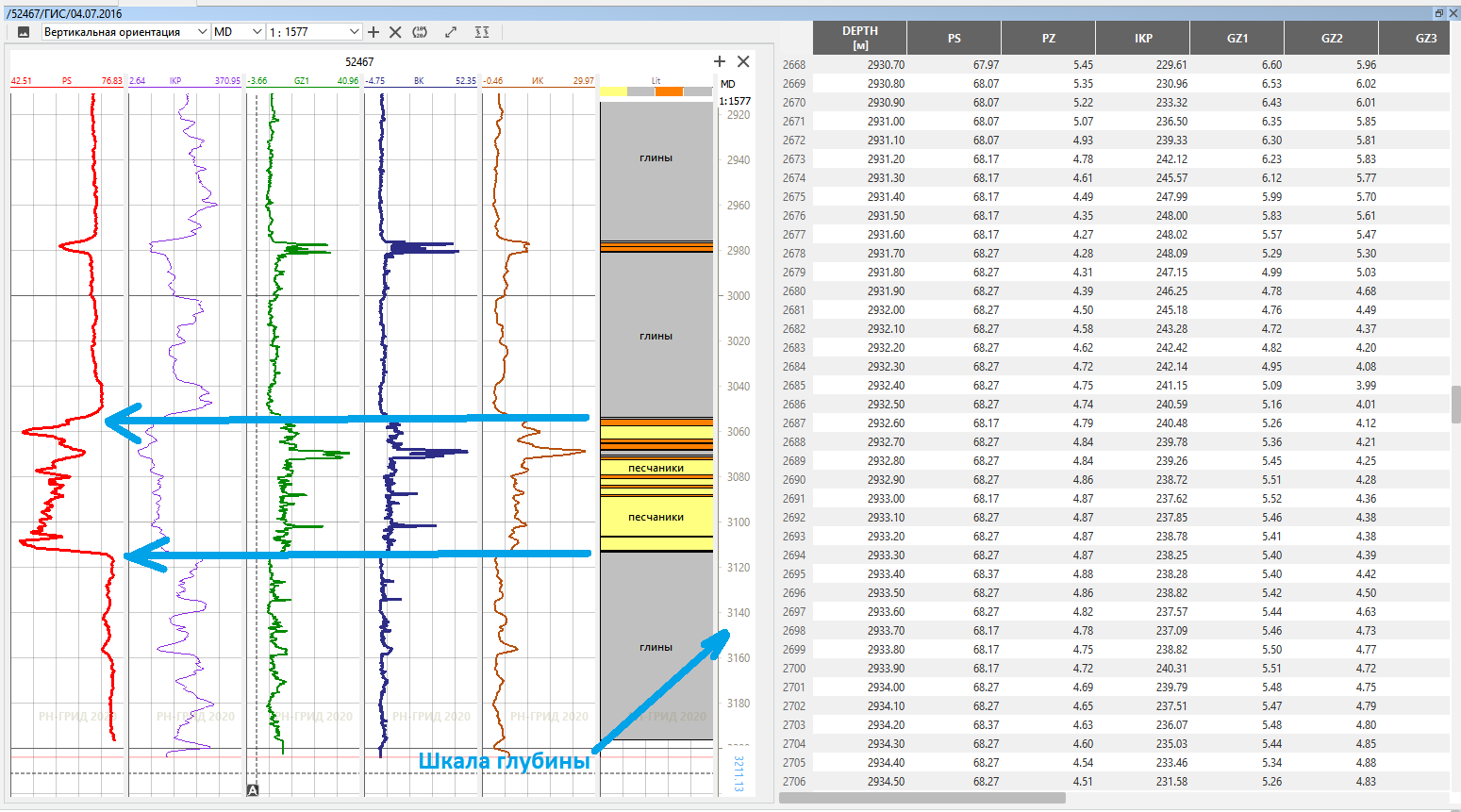
Then, exploratory drilling begins, and as the wells are drilled, instruments are lowered on a cable to measure all sorts of different indicators along the wellbore, that is, they conduct GIS (geophysical surveys of wells). The result of such a study is well logging, that is, a curve of a certain physical quantity measured with a certain step along the entire wellbore. Different instruments measure different quantities, and trained engineers then interpret these curves to obtain meaningful information. One instrument measures the natural gamma radioactivity of a rock. Clays “fonit” are stronger, sandstone “fonit” is weaker - any interpreter knows this and selects them on the logging curve: there are clays, here is a layer of sandstone, here is something in between. Another device measures the natural electrical potential between adjacent points,arising from the penetration of drilling fluid into the rock. The high potential shows the presence of a filtration connection between the formation points, the engineer knows and confirms the presence of permeable rock. The third device measures the resistance of the fluid saturating the rock: salt water passes current, oil does not pass current - and allows you to separate oil-saturated rocks from water-saturated rocks, and so on.
At this place, the data science engineers revived again, because the input for this problem is simple numerical curves, and replacing the interpreter with some ML-model that can draw conclusions about the rock properties instead of the engineer in the form of a curve means to solve classic classification problem. It is only later that data science engineers start to twitch their eyes when it turns out that some of these accumulated curves from old wells are only in the form of long paper footcloths.
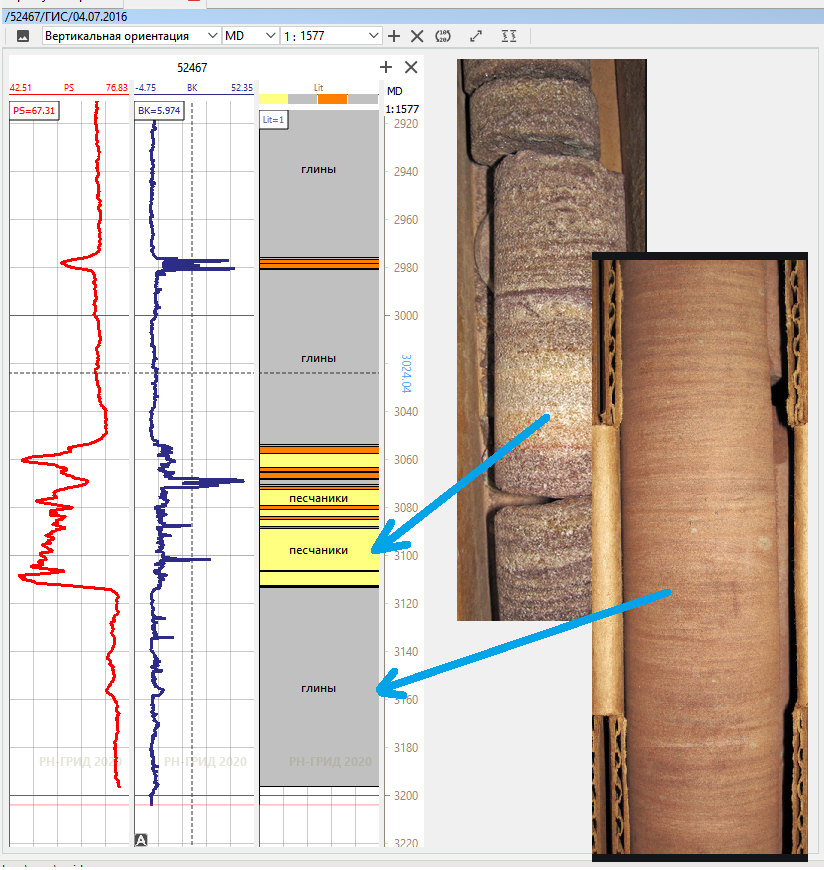
In addition, during drilling, a core is taken out of the well - samples of more or less intact (if lucky) and intact rock during drilling. These samples are sent to the laboratory, where they determine their porosity, permeability, saturation and all sorts of different mechanical properties. If it is known (and if carried out correctly, it should be known) from what depth a specific core sample was raised, then when the data from the laboratory come, it will be possible to compare what values at this depth were shown by all geophysical instruments, and what values of porosity, permeability and The rock had saturation at this depth according to core laboratory research. Thus, it is possible to “target” the readings of geophysical instruments and then only from their data, without having a core, draw a conclusion about the rock properties we need to build a model. The whole devil is in the details:the instruments measure not exactly what is determined in the laboratory, but this is a completely different story.
Thus, having drilled several wells and carried out research, we can confidently assert which rock and with what properties is located where these wells were drilled. The problem is that we do not know what is happening between the wells. And this is where the seismic model comes to our rescue.

At the wells, we know exactly what properties the rock has at what depth, but we do not know how the rock layers observed at the wells propagate and bend between them. The seismic model does not allow you to accurately determine which layer is located at what depth, but it confidently shows the nature of the propagation and bending of all layers at once, the nature of the bedding. Then the engineers mark certain characteristic points in the wells, placing markers at a certain depth: at this depth at this depth is the roof of the formation, at this depth is the bottom. And the surface of the roof and the sole between the wells, roughly speaking, is drawn parallel to the surface that is seen in the seismic model. The result is a set of three-dimensional surfaces that cover in space those of interest to us, and we are interested, of course, in formations containing oil. That,what happened is called a structural model, because it describes the structure of the reservoir, but not its internal content. The structural model says nothing about porosity and permeability, saturation and pressure within the reservoir.
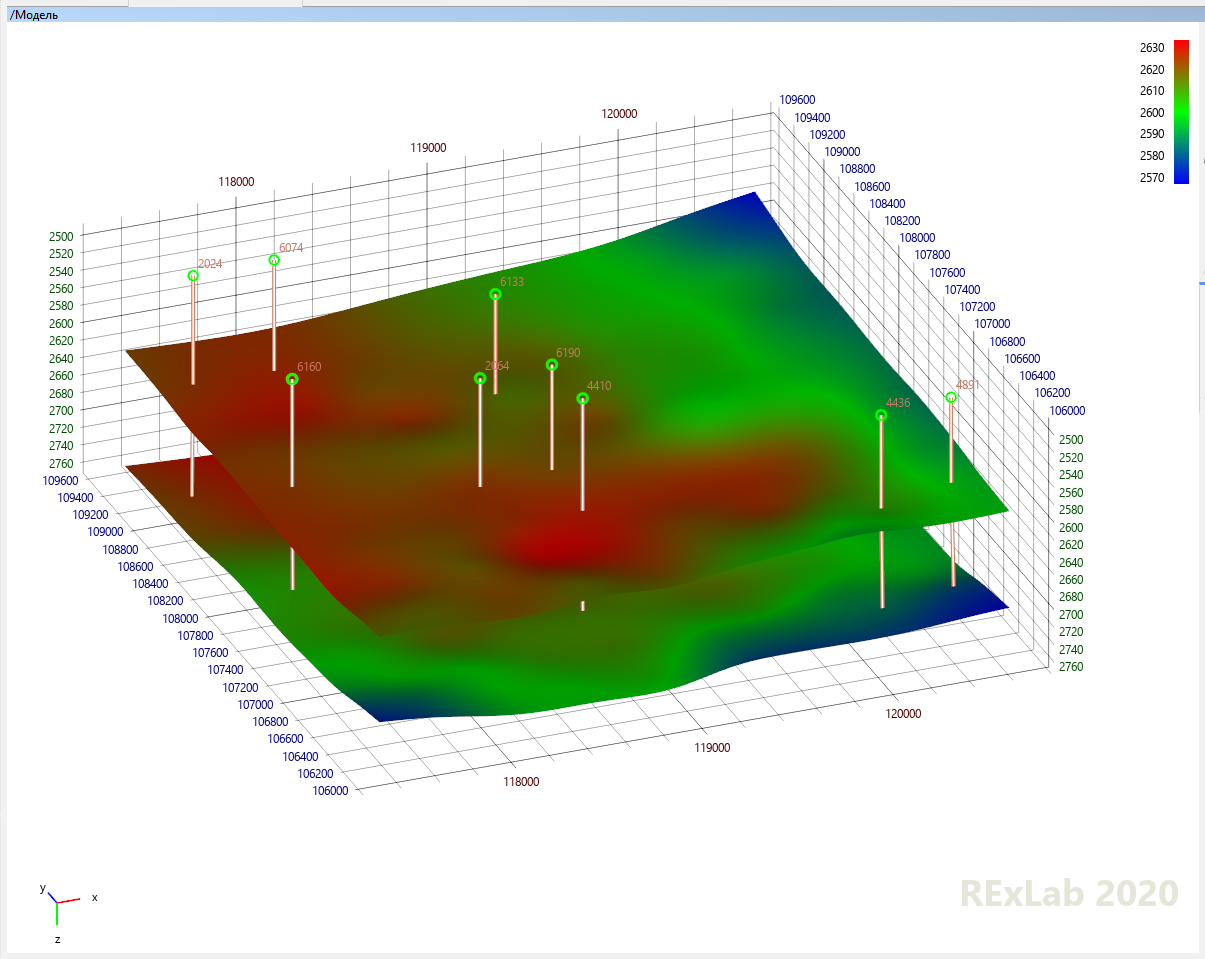
Then comes the stage of discretization, in which the area of space occupied by the field is divided into such a curved parallelepiped of cells (the nature of which is visible even on the seismic model!) In accordance with the occurrence of layers. Each cell of this curved parallelepiped is uniquely identified by three numbers, I, J and K. All layers of this curved parallelepiped lie according to the distribution of layers, and the number of layers in K and the number of cells in I and J is determined by the detail that we can afford.
How much detailed rock information do we have along the wellbore, that is, vertically? As detailed as how often the geophysical instrument measured its size while moving along the wellbore, that is, as a rule, every 20-40 cm, so each layer can be 40 cm or 1 m.
How detailed do we have information laterally, that is, away from the well? Not at all: away from the well, we have no information, so it makes no sense to divide into very small cells along I and J, and most often they are 50 or 100 m in both coordinates. Choosing the size of these cells is one of the important engineering tasks.
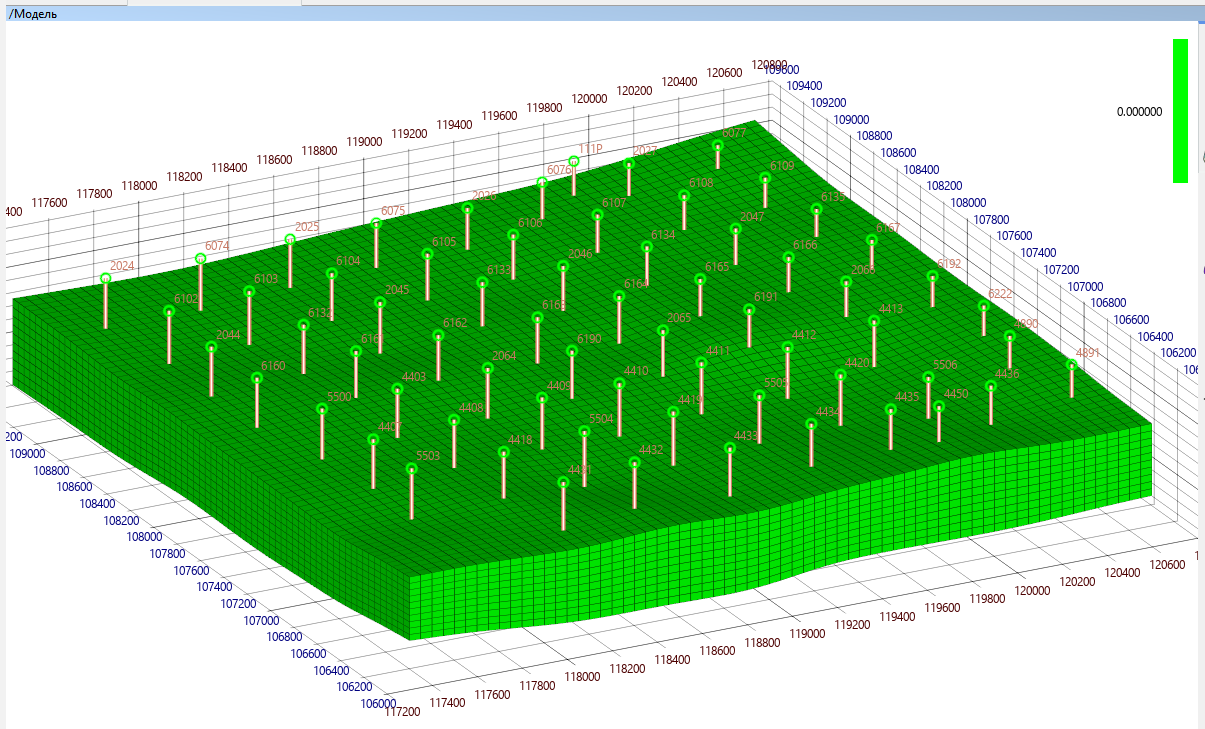
After the entire area of space is divided into cells, the expected simplification is made: within each cell, the value of any of the parameters (porosity, permeability, pressure, saturation, etc.) is considered constant. Of course, this is not so in reality, but since we know that the accumulation of sediments at the bottom of the sea went in layers, the rock properties will change much more vertically than horizontally.
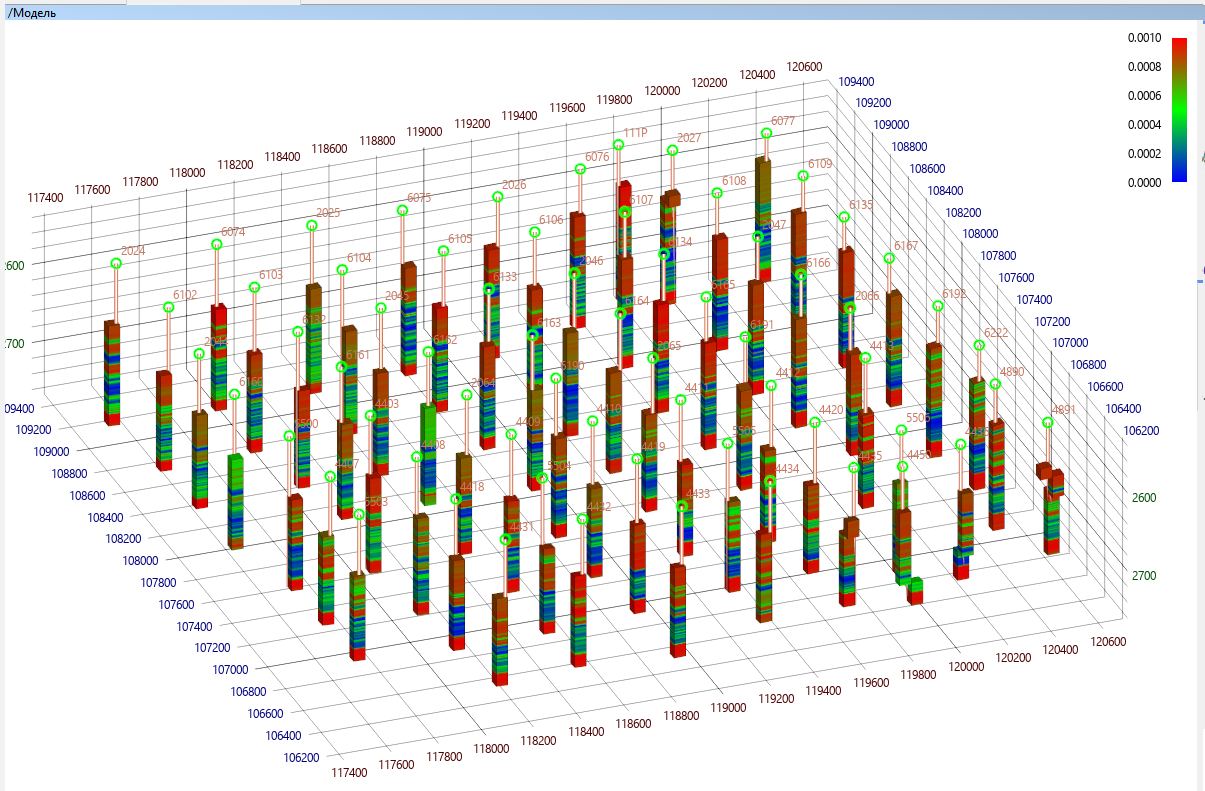
So, we have a grid of cells, each cell has its own (unknown to us) value of each of the important parameters describing both the rock and its saturation. So far, this grid is empty, but wells pass through some cells, in which we passed the device and obtained the values of the curves of geophysical parameters. Interpretation engineers, using laboratory core studies, correlations, experience, and such and such a mother, convert the values of the curves of geophysical parameters to the values of the characteristics of the rock and saturating fluid that we need, and transfer these values from the well to the grid cells through which this well passes. It turns out a grid, which in some places in the cells has values, but in most cells there are still no values. The values in all other cells will have to be imagined using interpolation and extrapolation. The experience of a geologist, his knowledge ofhow rock properties are generally propagated allows you to select the correct interpolation algorithms and fill in their parameters correctly. But in any case, we have to remember that all this is speculation about the unknown that lies between the wells, and it’s not in vain that they say, once again I will remind you of this common truth that two geologists will have three different opinions about the same deposit.
The result of this work will be a geological model - a three-dimensional curved parallelepiped, divided into cells, describing the structure of the field and several three-dimensional arrays of properties in these cells: most often these are arrays of porosity, permeability, saturation and the attribute "sandstone" - "clay".
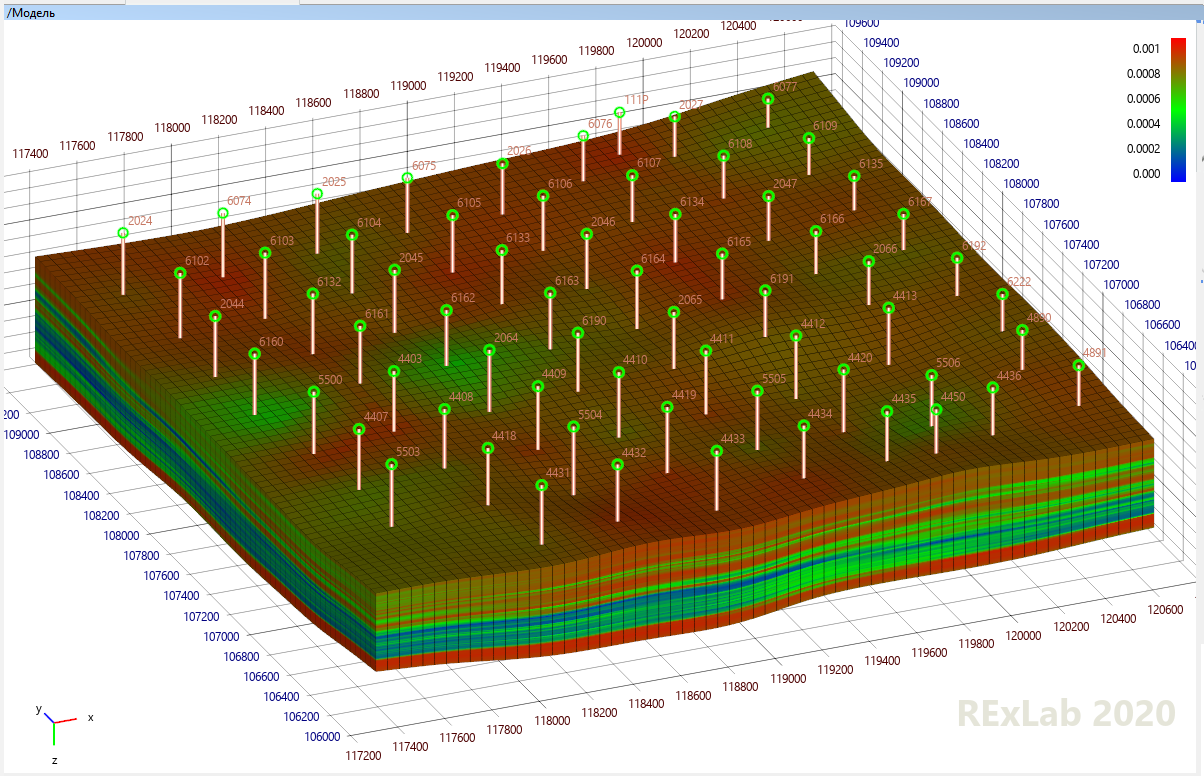
Then the hydrodynamic specialists take over. They can enlarge the geological model by combining several layers vertically and recounting the properties of the rock (this is called “upscaling”, and this is a separate difficult task). Then they add the rest of the necessary properties so that the hydrodynamic simulator can simulate what will flow where: in addition to porosity, permeability, oil, water, gas saturation, these will be pressure, gas content, and so on. They will add wells to the model and enter information on them about when and in what mode they worked. Have you forgotten that we are trying to reproduce history in order to have hope for a correct forecast? Fluid dynamics will take reports from the laboratory and add the physicochemical properties of oil, water, gas and rock to the model,all their dependencies (most often on pressure) and everything that happened, and it will be a hydrodynamic model, will be sent to a hydrodynamic simulator. He will honestly calculate from which cell to which everything will flow at what point in time, give out graphs of technological indicators for each well and scrupulously compare them with real historical data. The hydrodynamic engineer will sigh, looking at their discrepancy, and will go to change all the undefined parameters that he is trying to guess so that the next time the simulator is launched, he will get something close to the actually observed data. Or maybe the next time you start. Or maybe next time, and so on.will issue graphs of technological indicators for each well and meticulously compare them with real historical data. The hydrodynamic engineer will sigh, looking at their discrepancy, and will go to change all the undefined parameters that he is trying to guess so that the next time the simulator is launched, he will get something close to the actually observed data. Or maybe the next time you start. Or maybe the next and so on.will issue graphs of technological indicators for each well and meticulously compare them with real historical data. The hydrodynamic engineer will take a sigh, looking at their discrepancy, and go to change all the uncertain parameters that he is trying to guess so that the next time he starts the simulator, he will get something close to the real data observed. Or maybe the next time you start. Or maybe next time, and so on.
The engineer preparing the model of the surface infrastructure will take the flow rates that the field will produce according to the results of the modeling and put them into his model, which will calculate in which pipeline there will be what pressure and whether the existing pipeline system will be able to “digest” the production of the field: to clean the produced oil, prepare the required volume of injected water, and so on.
And finally, at the highest level, at the level of the economic model, the economist will calculate the flow of costs for the construction and maintenance of wells, electricity for the operation of pumps and pipelines and the flow of income from the delivery of produced oil to the pipeline system, multiply by the required degree of the discount factor and obtain the total NPV from a finished field development project.
The preparation of all these models, of course, requires the active use of databases for storing information, specialized engineering software that implements the processing of all input information and the actual modeling, that is, predicting the future from the past.
To build each of the above models, a separate software product is used, most often bourgeois, often practically uncontested and therefore very expensive. Such products have been developing for decades, and it is not easy to repeat their path with the help of a small institution. But dinosaurs were eaten not by other dinosaurs, but by small, hungry, purposeful ferrets. The important thing is that, as in the case of Excel, only 10% of functionality is needed for daily work, and our takes, like the Strugatskys, will be “only able to do that ... - but who can do it well” just these 10%. In general, we are full of hopes for which we already have certain grounds.
This article describes only one, the pillar path of the life cycle of the model of the entire field, and already there is a place for software developers to roam, and with current pricing models, competitors will have enough work for a long time. In the next article, there will be a spin-off
To be continued…