
Dodo Pizza has more than 600 pizzerias in 13 countries, and most of the processes in pizzerias are controlled by the Dodo IS information system , which we write and support. Therefore, the reliability and stability of the system is important for survival.
Now the stability and reliability of the information system in the company is supported by the SRE ( Site Reliability Engineering ) team , but this was not always the case.
Background: Parallel Worlds of Developers and Infrastructures
For many years I developed as a typical full-stack developer (and a bit of a scrum master), learned to write good code, applied practices from Extreme Programming, and diligently reduced the amount of WTF in projects I touched. But the more experience I gained in software development, the more I realized the importance of reliable monitoring and tracing systems for applications, high-quality logs, total automatic testing and mechanisms that ensure high reliability of services. And more and more often he began to peer “over the fence” to the infrastructure team.
The better I understood the environment in which my code works, the more I was surprised: automatic tests for everything and everything, CI, frequent releases, safe refactoring and collective code ownership in the software world have long been routine and familiar. At the same time, in the world of "infrastructure" it is still normal to lack automatic tests, to make changes to production systems in a semi-manual mode, and documentation is often only in the heads of individuals, but not in the code.
This cultural and technological divide causes not only confusion, but also problems: at the intersection of development, infrastructure and business. Some of the infrastructure problems are difficult to deal with due to proximity to hardware and relatively poorly developed tools. But the rest can be defeated if you start looking at all your Ansible playbooks and Bash scripts as a full-fledged software product and apply the same requirements to them.
Bermuda Triangle of Problems
However, I will start from afar - with the problems for which all these dances are needed.
Developer problems
Two years ago, we realized that a large pizza chain cannot live without its own mobile application and decided to write it:
- put together a great team;
- for six months they wrote a convenient and beautiful application;
- backed up the grand launch with delicious promotions;
- and on the first day safely fell under load.
There were, of course, a lot of shoals at the start, but most of all I remember one. At the time of development, a weak server was deployed on production, almost a calculator that processed requests from the application. Before the public announcement of the application, it had to be increased - we live in Azure, and this was solved with the click of a button.
But no one pressed this button: the infrastructure team did not even know that some kind of application would be released today. They decided that it was the responsibility of the application team to oversee the production of the "non-critical" service. And the backend developer (this was his first project in Dodo) decided that the guys from the infrastructure are doing this in large companies.
That developer was me. Then I deduced for myself an obvious but important rule:
, , , . .
Now it is not difficult. In recent years, a huge number of tools have appeared that allow programmers to look into the world of exploitation and not break anything: Prometheus, Zipkin, Jaeger, ELK stack, Kusto.
Nevertheless, many developers still have serious problems with what are called infrastructure / DevOps / SREs. As a result, programmers:
Depend on the infrastructure team. This causes pain, misunderstandings, sometimes mutual hatred.
They design their systems in isolation from reality and do not take into account where and how their code will be executed. For example, the architecture and design of a system that is being developed for life in the cloud will differ from that of a system that is hosted on-premise.
They don't understand the nature of bugs and problems associated with their code.This is especially noticeable when problems are related to load, query balancing, network or hard drive performance. Developers don't always have this knowledge.
They cannot optimize the money and other resources of the company that are used to maintain their code. In our experience, it happens that the infrastructure team simply floods the problem with money, for example, increasing the size of the database server in production. Therefore, code problems often don't even reach programmers. Just for some reason, the infrastructure is starting to cost more.
Infrastructure problems
There are also difficulties “on the other side”.
It is difficult to manage dozens of services and environments without quality code. We have more than 450 repositories on GitHub. Some of them do not require operational support, some are dead and saved for history, but a significant part contains services that need to be supported. They need to be hosted somewhere, they need monitoring, collection of logs, uniform CI / CD pipelines.
To manage all this, we recently actively used Ansible. Our Ansible repository contained:
- 60 roles;
- 102 playbooks;
- Python and Bash bindings
- manual tests in Vagrant.
It was all written by an intelligent person and written well. But, as soon as other developers from the infrastructure and programmers began to actively work with this code, it turned out that playbooks break, and roles are duplicated and "overgrown with moss."
The reason was that this code did not use many standard practices in the world of software development. It did not have a CI / CD pipeline, and the tests were complicated and slow, so everyone was too lazy or "no time" to run them manually, let alone write new ones. Such code is doomed if more than one person is working on it.
Without knowledge of the code, it is difficult to effectively respond to incidents.When an alert arrives at 3 a.m. in PagerDuty, you have to look for a programmer who will explain what and how. For example, that these 500 errors affect the user, while others are associated with a secondary service, end customers do not see it and you can leave everything like that until morning. But at three o'clock in the morning it is difficult to wake up programmers, so it is advisable to understand how the code that you support works.
Many tools require embedding in application code. The guys from the infrastructure know what to monitor, how to log and what things to pay attention to for tracing. But they often cannot embed all this into the application code. And those who can do not know what and how to embed.
"Broken phone."Explaining what and how to monitor for the hundredth time is unpleasant. It’s easier to write a shared library to pass it to programmers for reuse in their applications. But for this you need to be able to write code in the same language, in the same style and with the same approaches that the developers of your applications use.
Business problems
The business also has two big problems that need to be addressed.
Direct losses from system instability associated with reliability and availability.
In 2018, we had 51 critical incidents, and critical elements of the system did not work for more than 20 hours. In monetary terms, this is 25 million rubles of direct losses due to undelivered and undelivered orders. And how much we lost on the trust of employees, customers and franchisees is impossible to calculate, it is not evaluated in money.
Current infrastructure support costs. At the same time, the company set a goal for us for 2018: to reduce the cost of infrastructure per pizzeria by 3 times. But neither programmers nor DevOps engineers within their teams could even come close to solving this problem. There are reasons for this:
- , ;
- , operations ( DevOps), ;
- , .
?
How to solve all these problems? We found the solution in the book "Site Reliability Engineering" by Google. When we read it, we understood - this is what we need.
But there is a caveat - in order to implement all this, it takes years, and you have to start somewhere. Consider the source data that we had originally.
Our entire infrastructure lives almost entirely in Microsoft Azure. There are several independent sales clusters that are spread across different continents: Europe, America and China. There are load stands that repeat production, but live in an isolated environment, as well as dozens of DEV environments for development teams.
We have already had good SRE practices:
- mechanisms for monitoring applications and infrastructure (spoiler: in 2018 we thought they were good, but now we have already rewritten everything);
- 24/7 on-call;
- ;
- ;
- CI/CD- ;
- , ;
- SRE .
But there were also problems that I wanted to solve in the first place:
The infrastructure team was overloaded. There was not enough time and effort for global improvements due to the current operating system. For example, we wanted for a very long time, but could not get rid of Elasticsearch in our stack, or duplicate the infrastructure from another cloud provider in order to avoid risks (those who have already tried multicloud may laugh here).
Chaos in the code. The infrastructure code was chaotic, scattered across different repositories, and not documented anywhere. Everything rested on the knowledge of individuals and nothing else. This was a gigantic knowledge management problem.
"There are programmers and there are infrastructure engineers."Despite the fact that we had a fairly well-developed DevOps culture, there was still this separation. Two classes of people with completely different experiences, speaking different languages and using different tools. They, of course, are friends and communicate, but often do not understand each other due to completely different experiences.
SRE onboarding teams
To solve these problems and somehow start moving towards SRE, we launched an onboarding project. Only it was not classic onboarding - training new employees (newcomers) to add people to the current team. This was the creation of a new team of infrastructure engineers and programmers - the first step towards a full-fledged SRE structure.
We allocated 4 months to the project and set three goals:
- To train programmers with the knowledge and skills that are required for duty and operational activities in the infrastructure team.
- Write IaC - a description of the entire infrastructure in the code. And it should be a full-fledged software product with CI / CD, tests.
- Recreate our entire infrastructure from this code and forget about manually clicking virtual machines with the mouse in Azure.
Composition of participants: 9 people, 6 of them from the development team, 3 from the infrastructure. For 4 months, they had to leave their regular jobs and immerse themselves in the designated tasks. To maintain "life" in business, 3 more people from the infrastructure remained on duty, deal with operating systems and cover the rear. As a result, the project was noticeably stretched and took more than five months (from May to October 2019).
Two Pillars of Onboarding: Learning and Practice
Onboarding consisted of two parts: learning and working on the infrastructure in code.
Training. At least 3 hours a day were allocated for training:
- to read articles and books from the list of references: Linux, networks, SRE;
- at lectures on specific tools and technologies;
- to technology clubs, such as Linux, where we analyzed complex cases and cases.
Another learning tool is an internal demo. This is a weekly meeting where everyone (who has something to say) in 10 minutes talked about the technology or concept that he implemented in our code for the week. For example, Vasya changed the pipeline for working with Terraform modules, and Petya rewrote the image assembly using Packer.
After the demo, we started discussions under each topic in Slack, where interested participants could asynchronously discuss everything in more detail. So we avoided long meetings for 10 people, but at the same time everyone in the team understood well what was happening with our infrastructure and where we were heading.

Practice. The second part of onboarding is creating / describing the infrastructure in code . This part was divided into several stages.
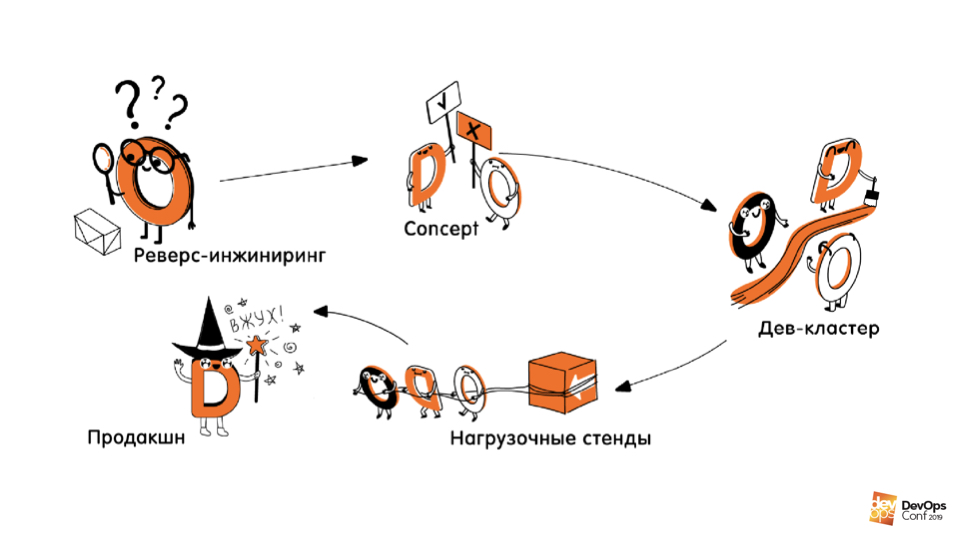
Reverse engineering of infrastructure.This is the first stage at which we have analyzed what is deployed where, how what works, where what services work, where what machines and their sizes. Everything is fully documented.
Concepts. We experimented with different technologies, languages, approaches, figured out how we can describe our infrastructure, what tools should be used for this.
Writing code. This included writing the code itself, creating CI / CD pipelines, tests, and building processes around it all. We wrote the code that described and knew how to create our dev infrastructure from scratch.
Re-creating stands for load testing and production.This is the fourth stage, which was supposed to go after onboarding, but it has been postponed for now, since the profit from it, oddly enough, is much less than from the virgin environments that are created / recreated very often.
Instead, we switched to project activities: we broke up into small subcommands and took up those global infrastructure projects that had not been reached before. And of course we joined the watch.
Our IaC tools
- Terraform .
- Packer Ansible .
- Jsonnet Python .
- Azure, .
- VS Code — IDE, , , , .
- — , .
Extreme Programming Practices in Infrastructure
The main thing that we, as programmers, brought with us is the Extreme Programming practices that we use in our work. XP is a flexible software development methodology that combines the squeeze of the best development approaches, practices and values.
There is not a single programmer who would not use at least some of the Extreme Programming practices, even if he does not know about it. At the same time, in the world of infrastructure, these practices are bypassed, despite the fact that they overlap to a very large extent with practices from Google SRE.
There is a separate article on how we adapted XP for infrastructure .... But in a nutshell: XP practices work for infrastructure code, albeit with restrictions, adaptations, but they work. If you want to apply them at home, invite people with experience in applying these practices. Most of these practices are described in one way or another in the same book about SRE .
It could have gone well, but it doesn't work that way.
Technical and anthropogenic problems on the way
There were two types of problems within the project:
- Technical : limitations of the “iron” world, lack of knowledge and raw tools that had to be used because there are no others. These are common problems for any programmer.
- Human : the interaction of people in a team. Communication, decision making, training. With this it was worse, so we need to dwell in more detail.
We began to develop the onboarding team the way we would do it with any other team of programmers. We expected that there would be the usual stages of building a Takman team : storming, normalization, and in the end we will go to productivity and productive work. Therefore, they did not worry that in the beginning there were some difficulties in communication, decision making, difficulties in order to agree.
Two months passed, but the storming phase continued. Only towards the end of the project did we realize that all the problems that we were struggling with and did not perceive as related to each other were the result of a common root problem - two groups of completely different people came together in the team:
- Experienced programmers with years of experience for which they developed their approaches, habits and values in work.
- Another group from the world of infrastructure with their own experience. They have different bumps, different habits, and they also think they know how to live right.
There was a clash of two views on life in one team. We did not see this immediately and did not start working with it, as a result of which we lost a lot of time, strength and nerves.
But this collision cannot be avoided. If you invite strong programmers and weak infrastructure engineers to the project, then you will have a one-way exchange of knowledge. On the contrary, it also does not work - some will swallow others and that's it. And you need to get some kind of mixture, so you need to be prepared for the fact that the “grinding” can be very long (in our case, we were able to stabilize the team only a year later, saying goodbye to one of the most technically powerful engineers).
If you want to assemble just such a team, do not forget to call a strong Agile coach, scrum master, or a psychotherapist - whichever you like best. Perhaps they will help.
Onboarding results
Based on the results of the onboarding project (it ended in October 2019), we:
- We have created a full-fledged software product that manages our DEV infrastructure, with its own CI pipeline, tests and other attributes of a quality software product.
- We doubled the number of people who are ready to be on duty and took the burden off the current team. After another six months, these people became full SREs. Now they can put out a fire on the market, consult a team of programmers on NTF, or write their own library for developers.
- SRE. , , .
- : , , , .
: ,
Several insights from the developer. Do not step on our rake, save yourself and others nerves and time.
Infrastructure is in the past. When I was in my freshman year (15 years ago) and started learning JavaScript, I had NotePad ++ and Firebug for debugging. Even then, it was necessary to do some complex and beautiful things with these tools.
About the same way I feel now when I work with infrastructure. Current tools are just being formed, many of them have not yet been released and have version 0.12 (hello Terraform), and many of them regularly break backward compatibility with previous versions.
For me, as an enterprise developer, using such things on the prod is absurd. But there are simply no others.
Read the documentation.As a programmer, I relatively rarely went to the docks. I knew my tools deeply enough: my favorite programming language, my favorite framework and databases. All additional tools, for example, libraries, are usually written in the same language, which means you can always look at the source. The IDE will always tell you which parameters are needed. Even if I'm wrong, I'll quickly figure it out by running quick tests.
This will not work in infrastructure, there are a huge number of different technologies that you need to know. But it is impossible to know everything deeply, and much is written in unknown languages. Therefore, carefully read (and write) the documentation - they will not live here for long without this habit.
Infrastructure code comments are inevitable.In the development world, comments are a sign of bad code. They quickly become outdated and start to lie. This is a sign that the developer could not otherwise express his thoughts. When working with the infrastructure, comments are also a sign of bad code, but you can’t do without them. For scattered instruments that are loosely related to each other and know nothing about each other, comments are indispensable.
Often the usual configs and DSL are hidden under the code. In this case, all the logic happens somewhere deeper where there is no access. This greatly changes the approach to code, testing and working with it.
Do not be afraid to let developers into the infrastructure.They can bring useful (and fresh) practices and approaches from the software development world. Use the practices and approaches from Google, described in the book on SRE, benefit and be happy.
PS: , , , .
PPS: DevOpsConf 2019 . , , : , , DevOps-, .
PPPS: , DevOps-, DevOps Live 2020. : , - . , DevOps-. — « » .
, DevOps Live , , CTO, .