Tips for separating distractions from useful information

If you take an introductory course in statistics, you will realize that the data can be used to find inspiration or test a theory, but never for both. Why is that?
People are too good at finding patterns in everything. You yourself determine which patterns really exist and which are invented. We are the creatures who find Elvis' face in a potato chip. If you are tempted to equate patterns to concepts, remember that there are three kinds of patterns:
- Patterns that exist both in your dataset and beyond.
- Patterns that only exist in your dataset.
- Patterns that only exist in your imagination (apophenia).
Data patterns can exist (1) in the entire population of interest, (2) only in a sample, or (3) only in your head.
What patterns and data patterns can be useful for you? It depends on your goals.
Inspiration
If you need pure inspiration, data can work wonders. Even apophenia (the human tendency to mistakenly perceive the connections and meaning between unrelated things) - can make your creative work to its fullest. Creativity does not have the right answers, so all you have to do is look at your data and play with them. As an added bonus, try not to waste too much time (yours or those of those concerned).
Facts
When your government wants to collect taxes from you, it cannot ignore the values that go beyond your financial data for the year. The tax service needs to make a factual decision on how much you owe and the main way to make this decision is to analyze data from last year. In other words, look at the data and apply the formula. In this case, we are talking about purely descriptive analytics, tied to the available data. Any of the first two types of patterns is well suited for this.
Descriptive analytics tied to existing data.
(I have never hidden my financial statements, but I think the United States government would not be thrilled if I used the data calculation methods I learned in graduate school to pay taxes statistically to replace them.)
Uncertainty Solutions
Sometimes the facts do not coincide with the desired. When you do not have all the information necessary to make a decision, you should be guided by uncertainty, trying to choose a reasonable course of action.
This is what statistics is about - the science of how to change your mind in the face of uncertainty. The game is about jumping into the unknown like Icarus ... and not being smashed to smithereens.
This is the main challenge of data science: how not to be * ignorant * as a result of data science.
Before jumping from this cliff, it is better to hope that the patterns that you found in your limited view of reality actually work outside of your view. In other words, templates need to be generalized to be useful to you.

Of the three types of patterns, when making decisions under uncertainty, only the first (generalized) one is safe. Unfortunately, you will find other types of patterns in your data - this is the big problem underlying data science: how not to lose your own awareness as a result of studying the data.
Generalization
If you think that finding useless patterns in data is a purely human privilege - think again! If you're not careful, machines can do the same thing automatically.
The whole point of machine learning and AI is to properly generalize new situations.
Machine learning is an approach to making a lot of similar decisions that involves algorithmic searching for patterns in your data and using them to correctly respond to completely new data. In machine learning and AI jargon, generalization refers to the ability of your model to perform well with data it hasn't seen before. What is the point of a template-based model that only works successfully with old data? To do this, you can simply use the lookup table. The whole point of machine learning and AI is to do the right generalizations in new situations.

This is why the first type of pattern on our list is the only one that works well for machine learning. This kind of data is a signal, everything else is just noise (factors that exist only in your old data and interfere with creating a generalizable model).
Signal: Patterns that exist both within your dataset and beyond.
Noise: Patterns that only exist in your dataset.
Basically, getting a solution that handles old noises, not new data, is what is called overfitting in machine learning (we use this term in the same tone you use to pronounce your favorite swear word). In machine learning learning, almost everything is done to avoid overfitting.
So what kind does * this * sample belong to?
Suppose the pattern that you (or your computer) has extracted from your data exists beyond your imagination - what category does it belong to? Is it a real phenomenon that exists in the population of interest (signal) or is it a feature of your dataset (noise)? How do you determine the type of pattern found when working with data?
If you study all the available data, then you will not be able to do this. You will be stumped and unable to tell if your template exists elsewhere. All rhetoric about testing statistical hypotheses depends on the unexpected, and to pretend that the already known pattern surprises you is bad taste (in fact, this is hacking).

It's like seeing a rabbit-shaped cloud and then checking to see if all the clouds look like rabbits ... looking at the same cloud. I hope you understand that you will need new clouds to test your theory.
Any data used to formulate a theory or a question cannot be used to verify the same theory.
What would you do if you knew that you only have access to one cloud? Meditated in the pantry, that's what. Ask your question before you look at the data.
Math never contradicts common sense.
Here we come to the saddest conclusion. If you use your dataset for inspiration, then you can't use it again to thoroughly test the theory it inspired (no matter what math jiu-jitsu tricks you use, math never goes against common sense).
Hard choice
The point is you have to make a choice! If you only have one dataset, then you have to ask yourself, “I meditate in the closet, formulating my hypotheses for statistical testing, and then gently take a rigorous approach — all so I can take myself seriously? Or am I just collecting data for inspiration, and in doing so I realize that I may be deceiving myself and remember that I should use phrases like 'I feel' or 'it inspires' or 'I'm not sure'? " Hard choice!
Or is there a way to eat one piece of cake twice? The problem is that you only have one dataset, and you need more than one dataset. And if you have enough data, then I have a trick that. Will blow up. Your. Brain.

Tricky trick
To be successful in data science, simply turn one dataset into two (at least) by splitting your data. Then use one for inspiration and the other for rigorous testing. If the pattern that initially inspired you also exists in the data that could not influence your opinion, then it is likely that this pattern is a general rule in force in the cat litter from which you take your data.
If the same phenomenon is observed in both data sets, this is probably a general rule that manifests itself in all sources of these data.
RSChD!
Since life without exploration is not life at all, here are four words to live by: Share your damn data .
The world would be a better place if everyone shared their data. We would have better answers (thanks to statistics) and better questions (thanks to analytics). The only reason people don't see data sharing as a mandatory habit is because in the last century it was a luxury that very few people could afford. The datasets were so small that if you tried to split them, there might be nothing left of them.
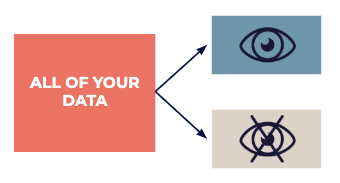
Separate your data into a research data set available to everyone that can be used for inspiration, and a test one, which will subsequently be used by experts to accurately confirm any “guesses” found at the research stage.
Some projects still face this problem, especially in medical research (I used to be in neuroscience, so I have a lot of respect for the complexity of working with small datasets), but many of you have so much data that you need to hire engineers. just to arrange for them to be moved ... what's your excuse ?! Do not skimp, share your data.
If you don’t have the habit of sharing data, you may be stuck in the 20th century.
If you have a lot of data, and their sets are not divided, then you exist in an outdated paradigm. People existing in this paradigm have come to terms with archaic thinking and refused to move further in time.
Machine learning - a descendant of data partitioning
In the end, the idea is simple. Use one dataset to form a theory, figure out that dataset, and then do the magic - prove your ideas on a whole new dataset.
Data sharing is the simplest fast solution for a healthier data culture.
This way you can safely use statistically methods and insure yourself against overfitting. In fact, the history of machine learning is the history of data sharing.
How to use the best idea in data science
To take advantage of the best idea in data science, all you have to do is make sure you keep test data out of the reach of prying eyes, and then let your analysts go crazy over everything else.
To succeed in data science, just turn one data set into (at least) two by dividing your data.
When you think they've brought you useful information beyond what they've learned, use your secret stash of test data to test your findings.

Find out the details of how to get a high-profile profession from scratch or Level Up in skills and salary by taking SkillFactory's paid online courses:
- Machine Learning Course (12 weeks)
- Learning Data Science from scratch (12 months)
- (9 )
- «Python -» (9 )
- Data Sciene 2020
- Data Science . Business Science
- Data Scientist
- Data Scientist -
- Data Science
- Data Science : «data»
- Data Sciene : Decision Intelligence