What is human speech? These are words, the combinations of which allow you to express this or that information. The question is, how do we know when one word ends and another begins? The question is rather strange, many will think, because from birth we hear the speech of the people around us, we learn to speak, write and read. The accumulated baggage of linguistic knowledge, of course, plays an important role, but in addition there are neural networks in the brain that divide the flow of speech into component words and / or syllables. Today we will get acquainted with a study in which scientists from the University of Geneva (Switzerland) created a neurocomputer model of speech decoding by predicting words and syllables. What brain processes became the basis of the model, what is meant by the big word "prediction",and how effective is the created model? The answers to these questions await us in the report of scientists. Go.
Basis of research
For us humans, human speech is quite understandable and articulate (most often). But for a machine, this is just a stream of acoustic information, a solid signal that needs to be decoded before being understood.
The human brain acts in much the same way, it just happens extremely quickly and imperceptibly for us. Scientists believe that the foundation of this and many other brain processes are certain neuronal oscillations, as well as their combinations.
In particular, speech recognition is associated with a combination of theta and gamma oscillations, since it allows hierarchically coordinating the encoding of phonemes in syllables without prior knowledge of their duration and temporal origin, i.e. upstream processing * in real time.
* (bottom-up) — , .Natural speech recognition also relies heavily on contextual cues to predict the content and temporal structure of the speech signal. Previous studies have shown that the prediction mechanism plays an important role during the perception of continuous speech. This process is associated with beta vibrations.
Another important component of speech recognition can be called predictive coding, when the brain constantly generates and updates a mental model of the environment. This model is used to generate touch predictions that are compared to actual touch input. Comparison of the predicted and actual signal leads to the identification of errors that serve to update and revise the mental model.
In other words, the brain is always learning something new, constantly updating the model of the surrounding world. This process is considered critical in the processing of speech signals.
The researchers note that many theoretical studies support both bottom-up and top-down * approaches to speech processing.
Downward processing * ( top-down ) - analysis of system components for the submission of its composite subsystems way reverse engineering.A previously developed neurocomputer model, involving the connection of realistic theta and gamma excitatory / inhibitory networks, was able to pre-process speech so that it could then be correctly decoded.
Another model, based solely on predictive coding, could accurately recognize individual speech elements (such as words or complete sentences, if we consider them as one speech element).
Therefore, both models worked, just in different directions. One focused on the real-time speech analysis aspect, and the other focused on the recognition of isolated speech segments (no analysis required).
But what if we combine the basic principles of these radically different models into one? According to the authors of the study we are considering, this will improve the performance and increase the biological realism of neurocomputer speech processing models.
In their work, the scientists decided to test whether a predictive coding-based speech recognition system can get some benefit from the processes of neural oscillations.
They developed the neurocomputer model Precoss (from predictive coding and oscillations for speech ), based on the predictive coding structure, to which they added theta and gamma oscillatory functions to cope with the continuous nature of natural speech.
The specific goal of this work was to find an answer to the question whether the combination of predictive coding and neural oscillations could be beneficial for the operational identification of syllabic components of natural sentences. In particular, the mechanisms by which theta waves can interact with upstream and downstream information streams were considered, and the impact of this interaction on the efficiency of the syllable decoding process was evaluated.
Architecture Precoss Models
An important function of the model is that it should be able to use the temporary signals / information present in continuous speech to determine syllable boundaries. Scientists have suggested that internal generative models, including temporal predictions, should benefit from such signals. To accommodate this hypothesis, as well as the repetitive processes that occur during speech recognition, a continuous predictive coding model was used.
The developed model clearly separates “what” and “when”. “What” - refers to the identity of the syllable and its spectral representation (not a temporary, but an ordered sequence of spectral vectors); “When” - refers to the prediction of the time and duration of syllables.
As a result, forecasts take two forms: the beginning of a syllable, signaled by the theta module; and syllable duration, signaled by exogenous / endogenous theta oscillations, which define the duration of the gamma-synchronized unit sequence (diagram below).
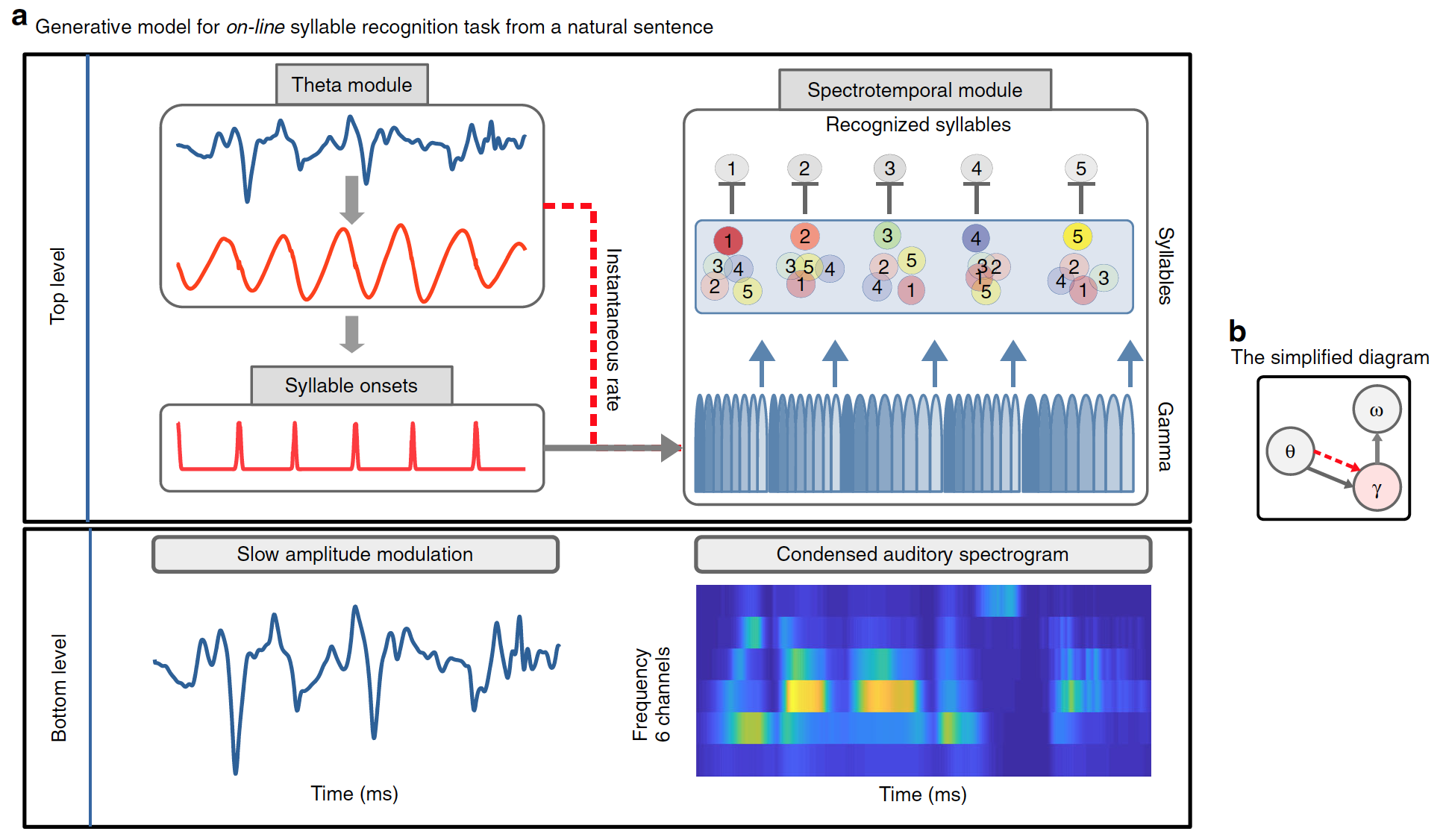
Image # 1
Precoss extracts a sensory signal from internal representations of its source by referring to a generative model. In this case, the touch input corresponds to the slow amplitude modulation of the speech signal and the 6-channel auditory spectrogram of the full natural sentence, which the model internally generates from four components:
- theta wobble;
- a slow amplitude modulation unit in a theta module;
- pool of syllable units (as many syllables as present in the natural introductory sentence, i.e. from 4 to 25);
- bank of eight gamma units in the spectrotemporal module.
Together, the units of syllables and gamma oscillations generate downward predictions regarding the input spectrogram. Each of the eight gamma units represents a phase in a syllable; they are activated sequentially, and the entire activation sequence is repeated. Therefore, each unit of a syllable is associated with a sequence of eight vectors (one per gamma unit) with six components each (one per frequency channel). The acoustic spectrogram of an individual syllable is generated by activating the corresponding syllable unit throughout the duration of the syllable.
While the block of syllables encodes a specific acoustic pattern, the gamma blocks temporarily use the appropriate spectral prediction over the duration of a syllable. Information about the length of a syllable is given by the theta wave, as its instantaneous velocity affects the speed / duration of the gamma sequence.
Finally, the accumulated data about the intended syllable must be deleted before processing the next syllable. To do this, the last (eighth) gamma block, which encodes the last part of a syllable, resets all syllable units to an overall low activation level, which allows new evidence to be collected.
Image No. 2
The performance of the model depends on whether the gamma sequence coincides with the beginning of a syllable and whether its duration matches the duration of a syllable (50–600 ms, average = 182 ms).
The estimation of the model with respect to the sequence of syllables is provided by the units of syllables, which together with the gamma units generate the expected spectro-temporal patterns (the result of the model's operation), which are compared with the input spectrogram. The model updates its estimates about the current syllable to minimize the difference between the generated and the actual spectrogram. The level of activity increases in those syllable units, the spectrogram of which corresponds to sensory input, and decreases in others. Ideally, minimizing the prediction error in real time leads to increased activity in one distinct unit of the syllable corresponding to the input syllable.
Simulation results
The model presented above includes physiologically motivated theta oscillations, which are controlled by slow amplitude modulations of the speech signal and transmit information about the beginning and duration of the syllable to the gamma component.
This theta-gamma relationship provides a temporal alignment of the internally generated predictions with the syllable boundaries found from the input data (option A in image # 3).
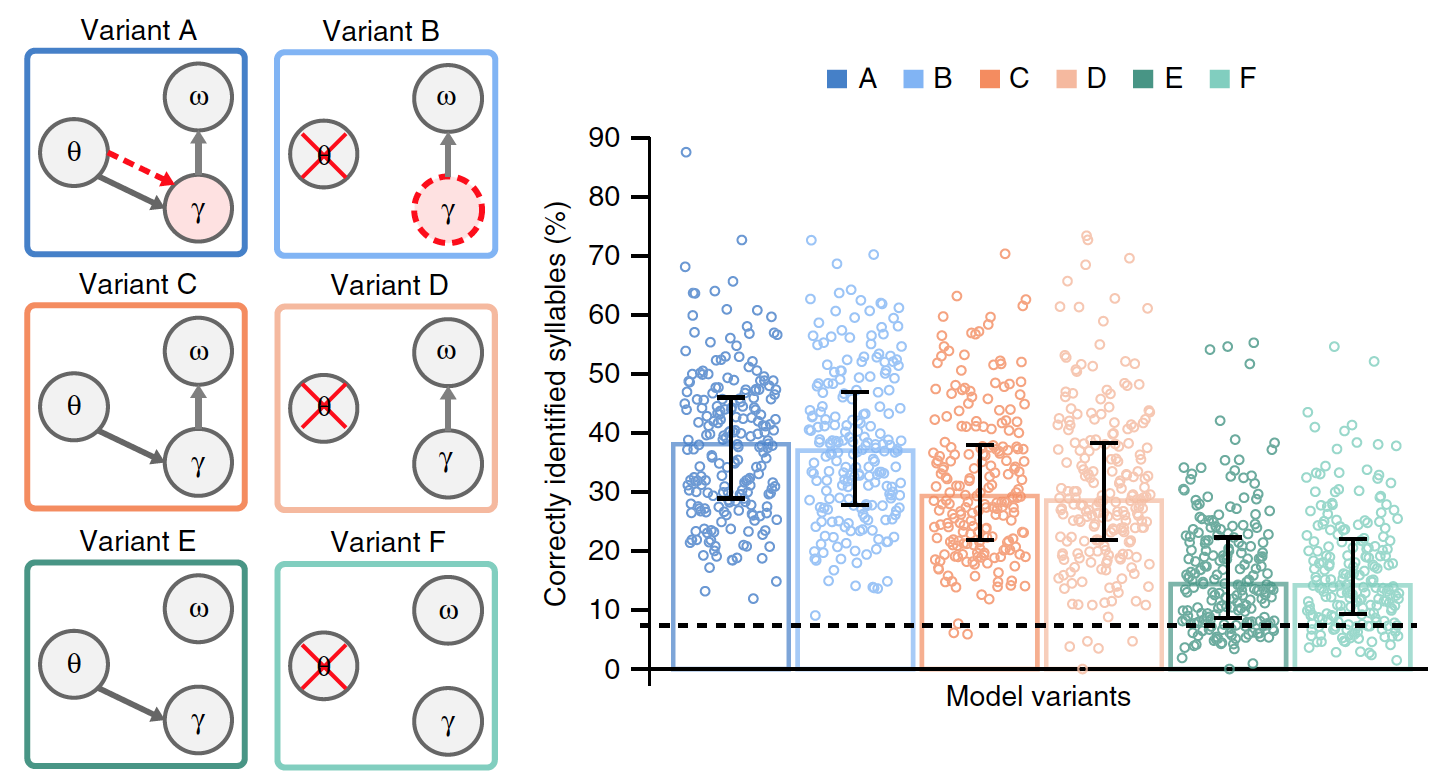
Image No. 3
To assess the relevance of syllable synchronization based on slow amplitude modulation, a comparison was made of model A with option B, in which theta activity is not modeled by vibrations, but arises from self-repetition of the gamma sequence.
In model B, the duration of the gamma sequence is no longer controlled exogenously (due to external factors) by theta oscillations, and endogenously (due to internal factors) it uses the preferred gamma speed, which, when the sequence is repeated, leads to the formation of an internal theta rhythm. As in the case of theta oscillations, the duration of the gamma sequence has a preferred speed in the theta range, which can potentially adapt to variable syllable durations. In this case, it is possible to test the theta rhythm arising from the repetition of the gamma sequence.
To more accurately assess the specific effects of theta-gamma conjunction and dumping of accumulated data in syllable units, additional variants of the previous models A and B were made.
Options C and D did not have a preferred gamma rate. Options E and F additionally differed from options C and D in the absence of resetting the accumulated data on syllables.
Of all the variants of the model, only A has a true theta-gamma relationship, where gamma activity is determined by the theta module, whereas in the B model, the gamma rate is set endogenously.
It was necessary to establish which version of the model is the most effective, for which a comparison was made of the results of their work in the presence of common input data (natural sentences). The graph in the image above shows the average performance of each of the models.
There were significant differences between the options. Compared to models A and B, performance was significantly lower in models E and F (23% on average) and C and D (15%). This indicates that erasing the accumulated data about the previous syllable before processing the new syllable is a critical factor in the encoding of the syllable stream in natural speech.
Comparison of options A and B with options C and D showed that theta-gamma association, whether stimulus (A) or endogenous (B), significantly improves model performance (on average by 8.6%).
Generally speaking, experiments with different versions of the models showed that it worked best when syllable units were reset after each gamma unit sequence was completed (based on internal information about the spectral structure of the syllable), and when the speed of gamma radiation was determined by the theta-gamma coupling.
The performance of the model with natural sentences, therefore, does not depend on the precise signaling of the onset of syllables by stimulus-driven theta oscillations, nor on the precise mechanism of theta-gamma relationship.
As the scientists themselves admit, this is a rather surprising discovery. On the other hand, the lack of performance differences between stimulus-driven and endogenous theta-gamma relationship reflects that the duration of syllables in natural speech is very close to the model's expectations, in which case there will be no advantage for the theta signal driven directly by the input data.
To better understand such an unexpected turn of events, scientists conducted another series of experiments, but with compressed speech signals (x2 and x3). As behavioral studies show, the understanding of speech compressed x2 does not practically change, but it drops dramatically when compressed by 3 times.
In this case, the stimulated theta-gamma connection can be extremely useful for parsing and decoding syllables. The simulation results are presented below.

Image No. 4
As expected, overall performance fell with increasing compression ratio. For x2 compression, there was still no significant difference between the stimulus and endogenous theta-gamma relationship. But in the case of compression x3 there is a significant difference. This suggests that the stimulus-driven theta wobble, driving the theta-gamma link, was more beneficial to the syllable encoding process than the endogenously set theta velocity.
It follows that natural speech can be processed with a relatively fixed endogenous theta generator. But for more complex input speech signals (i.e., when the speech rate is constantly changing), a controlled theta generator is required, which provides the gamma encoder with accurate temporal information about syllables (syllable start and syllable duration).
The model's ability to accurately recognize syllables in the input sentence does not account for the variable complexity of the various models being compared. Therefore, a Bayesian Information Criterion (BIC) was evaluated for each model. This criterion quantifies the trade-off between accuracy and complexity of the model (image # 5).
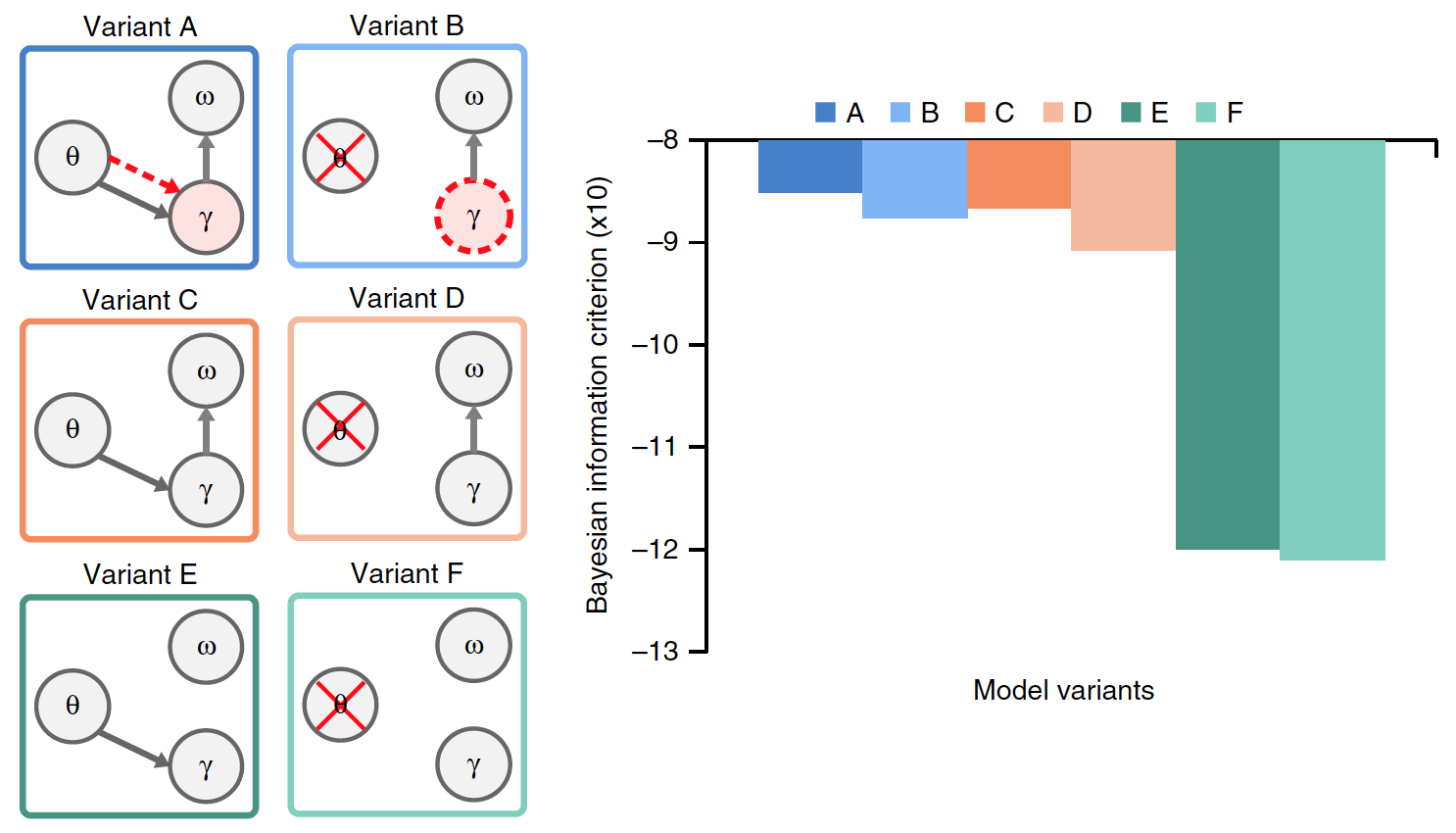
Image # 5
Option A showed the highest BIC values. Previous comparisons between Model A and Model B could not accurately distinguish between their performance. However, thanks to the BIC criterion, it became clear that variant A provides more confident syllable recognition than the model without stimulus-driven theta oscillations (model B).
For a more detailed familiarization with the nuances of the study, I recommend that you look into the report of scientists andadditional materials to it.
Epilogue
Summarizing the above results, we can say that the success of the model depends on two main factors. The first and most important is the dumping of accumulated data based on model information about the content of the syllable (in this case, its spectral structure). The second factor is the relationship between theta and gamma processes, which ensures that gamma activity is included in the theta cycle, corresponding to the expected duration of a syllable.
In essence, the developed model imitated the work of the human brain. The sound entering the system was modulated by a theta wave, reminiscent of neuronal activity. This allows you to determine the boundaries of syllables. Further, faster gamma waves help encode the syllable. In the process, the system suggests possible variants of syllables and corrects the choice if necessary. Jumping between the first and second levels (theta and gamma), the system detects the correct version of the syllable, and then zeroes out to start the process over for the next syllable.
During practical tests, it was possible to successfully decipher 2888 syllables (220 sentences of natural speech, English was used).
This study not only combined two opposing theories, putting them into practice as a single system, but also made it possible to better understand how our brain perceives speech signals. It seems to us that we perceive speech “as is”, i.e. without any complex auxiliary processes. However, taking into account the simulation results, it turns out that neural theta and gamma oscillations allow our brain to make small predictions about which syllable we hear, on the basis of which speech perception is formed.
Whoever says anything, but the human brain sometimes seems much more mysterious and incomprehensible than the unexplored corners of the Universe or the hopeless depths of the World Ocean.
Thank you for your attention, remain curious and have a good working week, guys. :)
A bit of advertising
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to your friends cloud-based VPS for developers from $ 4.99 , a unique analog of entry-level servers that was invented by us for you: The whole truth about VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps from $ 19 or how to divide the server? (options available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
Dell R730xd 2 times cheaper at the Equinix Tier IV data center in Amsterdam? Only we have 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV from $ 199 in the Netherlands!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - from $ 99! Read about How to build the infrastructure of bldg. class using Dell R730xd E5-2650 v4 servers costing 9,000 euros per penny?