
In our day-to-day work on Linux / Unix, we use many command line tools like du to monitor disk usage and system resources. Some of these tools have been around for a long time. For example, top appeared in 1984, and du's first release dates from 1971.
Over the years, these tools have been modernized and ported to different systems, but in general they have not gone far from their first versions, their appearance and usability have not changed much either.
These are great tools that many system administrators need. However, the community has developed alternative tools that offer additional benefits. Some of them just have a modern, beautiful interface, while others greatly improve the usability. In this translation, we will discuss five alternatives to the standard Linux command line tools.
1.ncdu vs du
NCurses Disk Usage ( ncdu ) is similar to du, but with an interactive curses-based interface. ncdu displays the directory structure that occupy most of your disk space.
ncdu analyzes the disk and then displays results sorted by the most commonly used directories or files, for example:
ncdu 1.14.2 ~ Use the arrow keys to navigate, press ? for help
--- /home/rgerardi ------------------------------------------------------------
96.7 GiB [##########] /libvirt
33.9 GiB [### ] /.crc
7.0 GiB [ ] /Projects
. 4.7 GiB [ ] /Downloads
. 3.9 GiB [ ] /.local
2.5 GiB [ ] /.minishift
2.4 GiB [ ] /.vagrant.d
. 1.9 GiB [ ] /.config
. 1.8 GiB [ ] /.cache
1.7 GiB [ ] /Videos
1.1 GiB [ ] /go
692.6 MiB [ ] /Documents
. 591.5 MiB [ ] /tmp
139.2 MiB [ ] /.var
104.4 MiB [ ] /.oh-my-zsh
82.0 MiB [ ] /scripts
55.8 MiB [ ] /.mozilla
54.6 MiB [ ] /.kube
41.8 MiB [ ] /.vim
31.5 MiB [ ] /.ansible
31.3 MiB [ ] /.gem
26.5 MiB [ ] /.VIM_UNDO_FILES
15.3 MiB [ ] /Personal
2.6 MiB [ ] .ansible_module_generated
1.4 MiB [ ] /backgrounds
944.0 KiB [ ] /Pictures
644.0 KiB [ ] .zsh_history
536.0 KiB [ ] /.ansible_async
Total disk usage: 159.4 GiB Apparent size: 280.8 GiB Items: 561540The entries can be navigated using the arrow keys. If you press Enter, ncdu will display the contents of the selected directory:
--- /home/rgerardi/libvirt ----------------------------------------------------
/..
91.3 GiB [##########] /images
5.3 GiB [ ] /mediaYou can use this tool to, for example, determine which files are taking up the most disk space. You can go to the previous directory by pressing the left arrow key. With ncdu, you can delete files by pressing d. Before deletion, it asks for confirmation. If you want to disable the delete function to prevent accidental loss of valuable files, use the -r option to enable read-only access mode: ncdu -r.
ncdu is available for many Linux platforms and distributions. For example, you can use dnf to install it on Fedora directly from the official repositories:
$ sudo dnf install ncdu2.htop vs top
Htop is an interactive process viewer, similar to top, but provides a pleasant user experience out of the box. By default, htop displays the same information as top, but in a more visual and colorful way.
By default, htop looks like this:
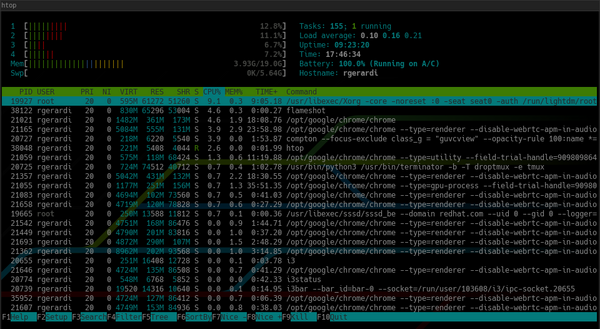
Unlike top:
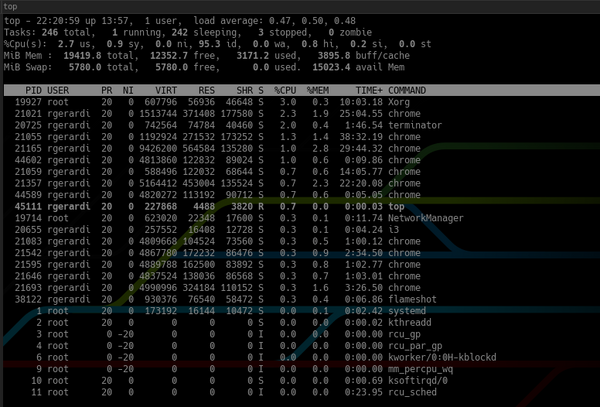
In addition, at the top, htop displays an overview of the system, and at the bottom, a panel for running commands using function keys. You can customize it by pressing F2 to open the customization screen. In the settings, you can change colors, add or remove metrics, or change the display options for the overview pane.
Although tweaking the settings of the latest versions of top can also achieve similar usability, htop provides convenient default configurations, which makes it more practical and easier to use.
3. tldr vs man
The tldr command line tool displays simplified command help information, mostly examples. It was developed by the tldr pages project community .
It's worth noting that tldr is not a replacement for man. It is still the canonical and most complete tool for displaying manual pages. However, in some cases, man is redundant. When you do not need comprehensive information about a command, you are just trying to remember the basic use cases. For example, the man page for curl is almost 3000 lines. The tldr page for curl is 40 lines long. Her fragment looks like this:
$ tldr curl
# curl
Transfers data from or to a server.
Supports most protocols, including HTTP, FTP, and POP3.
More information: <https://curl.haxx.se>.
- Download the contents of an URL to a file:
curl http://example.com -o filename
- Download a file, saving the output under the filename indicated by the URL:
curl -O http://example.com/filename
- Download a file, following [L]ocation redirects, and automatically [C]ontinuing (resuming) a previous file transfer:
curl -O -L -C - http://example.com/filename
- Send form-encoded data (POST request of type `application/x-www-form-urlencoded`):
curl -d 'name=bob' http://example.com/form
- Send a request with an extra header, using a custom HTTP method:
curl -H 'X-My-Header: 123' -X PUT http://example.com
- Send data in JSON format, specifying the appropriate content-type header:
curl -d '{"name":"bob"}' -H 'Content-Type: application/json' http://example.com/users/1234
... TRUNCATED OUTPUTTLDR means “too long; didn’t read ”: that is, some text was ignored due to its excessive verbosity. The name is appropriate for this tool because the man pages, while useful, are sometimes too long.
For Fedora, tldr was written in Python. You can install it using dnf manager. Typically, the tool requires access to the Internet. But the Fedora Python client allows you to download and cache these pages for offline access.
4.jq vs sed / grep
jq is a JSON processor for the command line. It is similar to sed or grep, but is specifically designed to work with JSON data. If you are a developer or sysadmin who uses JSON for your day to day tasks, this is the tool for you.
The main advantage of jq over standard text processing tools like grep and sed is that it understands the structure of JSON data, allowing you to create complex queries in a single statement.
For example, you are trying to find the names of containers in this JSON file:
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"labels": {
"app": "myapp"
},
"name": "myapp",
"namespace": "project1"
},
"spec": {
"containers": [
{
"command": [
"sleep",
"3000"
],
"image": "busybox",
"imagePullPolicy": "IfNotPresent",
"name": "busybox"
},
{
"name": "nginx",
"image": "nginx",
"resources": {},
"imagePullPolicy": "IfNotPresent"
}
],
"restartPolicy": "Never"
}
}Run grep to find the string name:
$ grep name k8s-pod.json
"name": "myapp",
"namespace": "project1"
"name": "busybox"
"name": "nginx",grep returned all lines containing the word name. You can add a few more options to grep to constrain it, and with some regular expression manipulation, find the container names.
To get the same result with jq, just write:
$ jq '.spec.containers[].name' k8s-pod.json
"busybox"
"nginx"This command will give you the names of both containers. If you are looking only for the name of the second container, add the index of the array element to the expression:
$ jq '.spec.containers[1].name' k8s-pod.json
"nginx"Since jq is aware of the data structure, it gives the same results even if the file format changes slightly. grep and sed may not work correctly in this case.
Jq has many functions, but another article is needed to describe them. For more information see the jq project page or tldr.
5. fd vs find
fd is a lightweight alternative to find. Fd is not intended to replace it entirely: it defaults to the most common settings that define the overall approach to working with files.
For example, when searching for files in a Git repository directory, fd will automatically exclude hidden files and subdirectories, including the .git directory, and ignore templates from the .gitignore file. In general, it speeds up the search by delivering more relevant results on the first try.
By default, fd performs case-insensitive searches in the current directory with color output. The same search using the find command requires additional parameters to be entered on the command line. For example, to find all .md (or .MD) files in the current directory, you would write the find command:
$ find . -iname "*.md"For fd, it looks like this:
$ fd .mdBut in some cases, fd also requires additional options: for example, if you want to include hidden files and directories, you must use the -H option, although this is usually not required for searches.
fd is available for many Linux distributions. In Fedora, you can install it like this:
$ sudo dnf install fd-findYou don't have to give up something
Are you using the new Linux command line tools? Or do you sit exclusively on old ones? But most likely you have a combo, right? Please share your experience in the comments.
Advertising
Many of our customers have already appreciated the benefits of epic servers !
These are virtual servers with AMD EPYC processors , CPU core frequency up to 3.4 GHz. The maximum configuration will allow you to come off to the full - 128 CPU cores, 512 GB RAM, 4000 GB NVMe. Hurry to order!
