At the end of the article, we will share with you a list of the most interesting materials on this topic.

New approach
Multi-agent reinforcement learning is a growing and rich area of research. Nevertheless, the constant use of single-agent algorithms in multi-agent contexts puts us in a difficult position. Learning is complicated for many reasons, especially due to:
- Nonstationarity between independent agents;
- The exponential growth of action spaces and states.
Researchers have found many ways to reduce the effects of these factors. Most of these methods fall under the concept of “central planning with decentralized execution.”
Centralized planning
Each agent has direct access to local observations. These observations can be very diverse: images of the environment, position relative to certain landmarks, or even position relative to other agents. In addition, during training, all agents are controlled by a central unit or critic.
Although each agent has only local information and local policies for training, there is an entity that monitors the entire system of agents and tells them how to update policies. Thus, the effect of non-stationarity is reduced. All agents are trained using the module with global information.
Decentralized execution
During testing, the central module is removed, and the agents with their policies and local data remain. This reduces the harm caused by the increasing spaces of actions and states, since the aggregate policies are never studied. Instead, we hope that there is enough information in the central module to drive the local learning policy so that it is optimal for the entire system as soon as it is time to test.
Openai
Researchers from OpenAI, the University of California at Berkeley and McGill University, have introduced a new approach to multi-agent settings using the Multi-Agent Deep Deterministic Policy Gradient . Inspired by its single-agent counterpart to DDPG, this approach uses “actor-critic” type training and shows very promising results.
Architecture
This article assumes that you are familiar with the single-agent version of MADDPG: Deep Deterministic Policy Gradients or DDPG. To refresh your memory, you can read the wonderful article by Chris Yoon .
Each agent has an observation space and a continuous action space. Also, each agent has three components:
- , ;
- ;
- , - Q-.
As the critic examines the joint Q-values of a function over time, he sends appropriate approximations of the Q-values to the actor to aid in learning. In the next section, we will examine this interaction in more detail.
Remember that a critic can be a common network between all N agents. In other words, instead of training N networks that evaluate the same value, just train one network and use it to help train all other agents. The same is true for networks of actors if the agents are homogeneous.
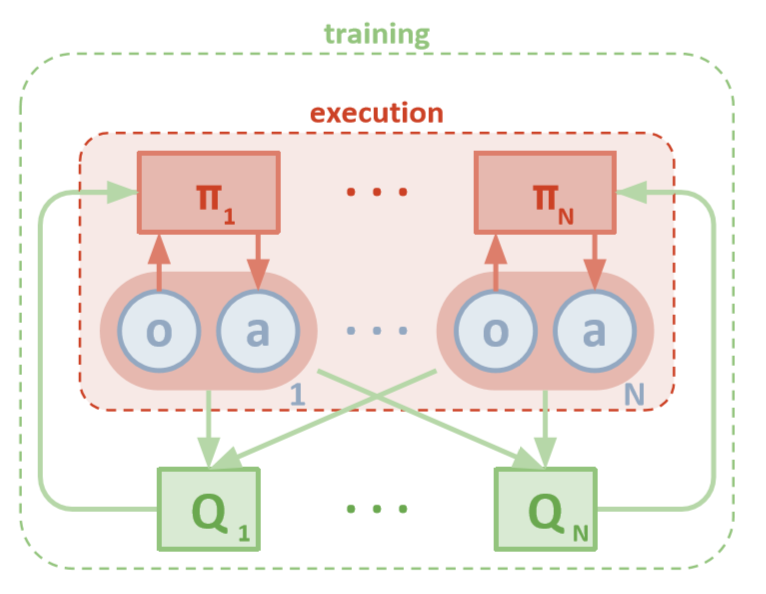
MADDPG Architecture (Lowe, 2018)
Training
First, MADDPG uses experience replay for effective off-policy learning. At each time interval, the agent stores the following transition:
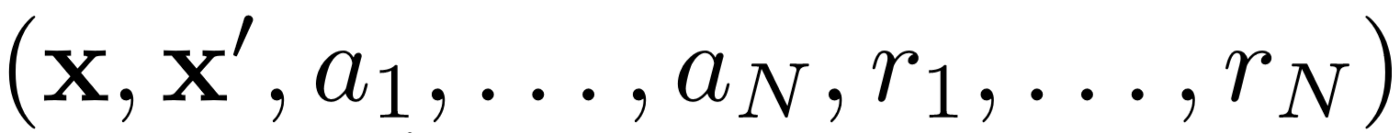
Where we store the joint state, the next joint state, joint action and each of the rewards received by the agent. Then we take a set of such transitions from experience replay to train our agent.
Criticism updates
To update the agent's central critic, we use a lookahead TD bug:
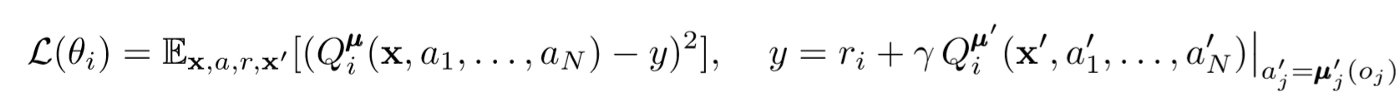
Where μ is an actor. Remember that this is a central critic, that is, he uses general information to update his parameters. The basic idea is that if you know the actions that all agents are taking, then the environment will be stationary even if the policy changes.
Pay attention to the right side of the expression with the calculation of the Q-value. While we never save our next synergy, we use each target actor of the agent to compute the next action during the update to make learning more stable. The target actor's parameters are periodically updated to match those of the agent's actor.
Actors Updates
Similar to single agent DDPG, we use a deterministic policy gradient to update each parameter of an agent actor.
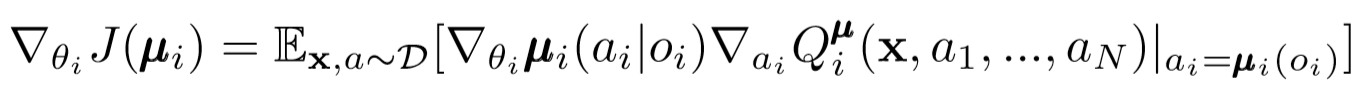
Where μ is an agent actor.
Let's go a little deeper into this expression of renewal. We take the gradient relative to the parameters of the actor with the help of a central critic. The most important thing to note is that even if the actor has only local observations and actions, during training we use a central critic to get information about the optimality of his actions within the whole system. This reduces the effect of non-stationarity, and the learning policy remains in the lower state space!
Conclusions from politicians and ensembles of politicians
We can take one more step on the issue of decentralization. In previous updates, we assumed that each agent would automatically recognize the actions of other agents. However, MADDPG suggests drawing conclusions from the policies of other agents to make learning even more independent. In fact, each agent will add N-1 networks to evaluate the policy validity of all other agents. We use a probabilistic network to maximize the logarithmic probability of inferring the observed action of another agent.
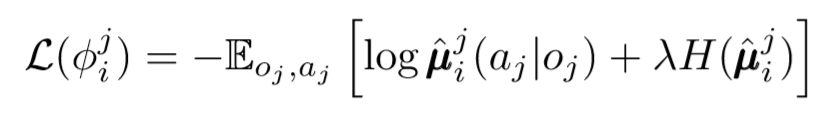
Where we see the loss function for the i-th agent evaluating the policy of the j-th agent using the entropy regularizer. As a result, our target Q-value becomes slightly different when we replace the agent’s actions with our predicted actions!
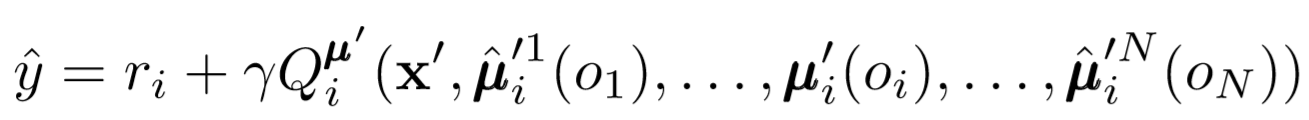
So what happened in the end? We removed the assumption that agents know each other's policies. Instead, we try to train agents to predict the policies of other agents based on a series of observations. In fact, each agent learns independently, receiving global information from the environment instead of just having it at hand by default.
Political Ensembles
There is one big problem in the above approach. In many multi-agent settings, especially competitive ones, agents can create policies that can retrain on the behavior of other agents. This will make the policy fragile, unstable, and generally sub-optimal. To compensate for this shortcoming, MADDPG trains a collection of K sub-policies for each agent. At each time step, the agent randomly selects one of the subpolicy to select an action. And then he does it.
The gradient of politics changes slightly. We take the average over K subpolicy, use wait linearity, and propagate updates using the Q-value function.
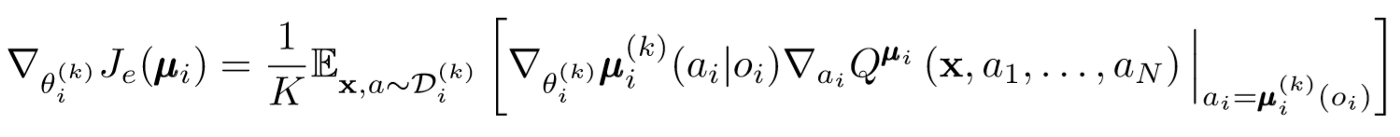
Let's take a step back
This is how the whole algorithm looks in general terms. Now we need to go back and realize what exactly we did and intuitively understand why it works. Basically, we did the following:
- Defined actors for agents who only use local observations. In this way, one can take control of the negative effect of exponentially increasing spaces of states and actions.
- A central criticism was identified for each agent that uses shared information. So we were able to reduce the effect of non-stationarity and helped the actor to become optimal for the global system.
- Defined policy inference networks to evaluate the policies of other agents. In this way, we were able to limit the interdependence of agents and eliminate the need for agents to have perfect information.
- The ensembles of policies were identified to reduce the effect and the possibility of retraining on the policies of other agents.
Each component of the algorithm serves a specific, distinct purpose. The MADDPG algorithm is powerful because of the following: its components are designed specifically to overcome the serious obstacles that usually confront multi-agent systems. Next, we'll talk about the performance of the algorithm.
results
MADDPG has been tested in many environments. A complete overview of his work can be found in the article [1]. Here we will only talk about the problem of cooperative communication.
Environment Overview
There are two agents: the speaker and the listener. At each iteration, the listener receives a colored dot on the map to which you want to move, and receives a reward proportional to the distance to this point. But here's the catch: the listener only knows his position and the color of the endpoints. He does not know what point he should move to. However, the speaker knows the color of the desired point for the current iteration. As a result, the two agents must interact to accomplish this task.
Comparison
To solve this problem, the article contrasts MADDPG and modern single-agent methods. Significant improvements are seen with the use of MADDPG.
It was also shown that inferences from policies, even if politicians were not trained ideally, achieved the same results that can be achieved using true observation. Moreover, there was no significant slowdown in convergence.
Finally, ensembles of politicians have shown very promising results. The article [1] explores the influence of ensembles in a competitive environment and demonstrates a significant performance improvement over agents with a single policy.
Conclusion
That's all. Here we looked at a new approach to multi-agent reinforcement learning. Of course, there are an infinite number of MARL-related methods, but MADDPG provides a solid foundation for methods that solve the most global problems of multi-agent systems.
Sources
[1] R. Lowe, Y. Wu, A. Tamar, J. Harb, P. Abbeel, I. Mordatch, Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments (2018).
List of useful articles
- 3 pitfalls for aspiring Data Scientists
- AdaBoost algorithm
- How was 2019 in Mathematics and Computer Science
- Machine learning faces unsolved math problem
- Understanding Bayes' Theorem
- Search for facial contours in one millisecond using an ensemble of regression trees
, , , . .