
In fact, this is the history of the search for a defect in the layout of a bank site, which led to an inaccurate display of its main page on search. A similar problem is often encountered on a site assembled, for example, in an online constructor, or designed, for example, by a layout designer who is not familiar with the basics of search engine optimization.
And this story would have remained interesting only to a narrow circle of practicing seoshniks, had it not touched one undocumented feature of indexing, which other website maintenance specialists would probably have wanted to know about. I invite them under the cat.
Short intro
Any experienced SEO-master knows the rules of semantic parsing of a website page by search engine crawlers. These rules are based on individual provisions of some technical standards on the Internet. For example:
- the <title> tag is a unique name for the entire document and is used only in its heading section, and only once;
- the <h1> tag headlines a specific section of the document and can be reused, but only in another section and while maintaining uniqueness among all <h1> tags of the same document;
- the <h2> tag is a section subheading that can be reused even in the same section, while maintaining uniqueness among the peer subheadings of its section;
- the <h3> tag is the subheading of the parent subheading;
- … etc.
Of course, there are different nuances in these rules for parsing pages before indexing them, which are interpreted by each search server in its own way:
- , «», — , <p> ;
- (outlines), «» — , <h2> <p> () ;
- … .
These rules of semantic analysis and nuances are not important to us yet. And if you are so interested in the very provisions of technical standards on which content indexing is based, then the main part of these provisions is quite clearly stated in the review publication [1] about the permissibility of several <h1> tags on one page of a site.
I just note that SEO-masters are accustomed to such nuances, this is not the first time they have checked their fairness on their own experience, and they have long been promoting websites in search taking into account a similar view on the priority of tags. After all, understanding the principles of indexing makes it possible to partially "control" the text that will show the site's search snippet in response to a user's request.
But here a few days ago insider information appeared that in the results of an organic search relating to the official website of the Ukrainian Monobank, an incomprehensible behavior of the snippet was revealed: the search engine didn’t title it at all by the <title> or <h1> tag. That is, the copywriter could write the most unique headline and text, the content manager could insert text on the site, but the search would still not be right.
It was necessary to figure out the reason, which I will talk about further.
The first step of research
So, first, I cleared the cache and browser history, restarted it, opened the Google search box and entered the name of the bank. So that even an inexperienced SEO person could understand my every step, I took a picture of the first step.
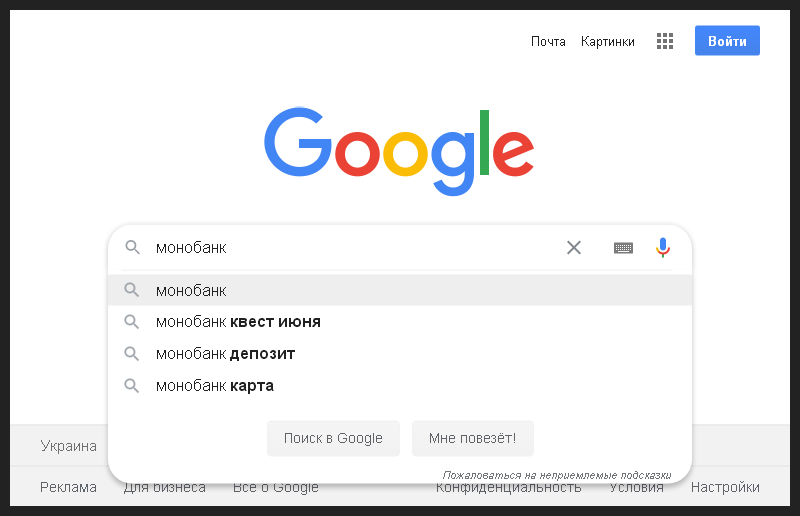
This is a branded information request, which means that in the first place of organic results, it is logical to expect a snippet for the bank's home page.
Everything happened as expected, the snippet was the first in the search, and it also contained a block of quick links to the main sections of the site. I captured this moment in the next picture.
So far, everything has looked normal.

In order to make sure that an obscure situation occurs only in Google’s results, I repeated the same query in Yandex search and pleasantly noted that this search giant adheres to the usual rules: the snippet was entitled monobank - a mobile bank - exactly as written in the <title> tag of the desired pages.

The answer on the Google search snapshot was fundamentally different, at least in terms of the title. And besides, I was somewhat confused by the ridiculous texts under the headings of the Google snippet.
I assumed that this is just a consequence of the fact that after SMM promoting the brand and its mobile application, which was implemented by Promodo in 2017-2018 [2] for the former monobank.com.ua domain , to hire more SEO-masters to service the new monobank domain .ua no longer made sense. After all, the advertising campaign has borne the expected results. And the bank’s leadership on the search promotion of the new domain, most likely, generally scored, or assigned the duty to full-time IT specialists.
Therefore, I attributed the clumsiness of the current texts to the understandable reluctance of regular employees to check the result of the request, which a typical bank user will never actually dial.
After all, the clientele of the bank goes to the site for the most part through a mobile application, practically without observing how the bank’s pages look in the search. And the part of clients who go through the Internet search mainly uses queries of the form:
- monobank dollar rate;
- monobank exchange rate;
- open a monobank account;
- make a monobank card;
- create a monobank card;
- monobank credit card;
- get a monobank loan;
- take out a monobank loan;
- … etc.
Any bank knows a complete list of such search phrases that match the "what to find + where" or "where + what" patterns and bring in the highest inbound traffic from organic search.
Checking Tasty Queries
How surprised I was when for most of these queries the same snippet appeared in the search results with an invariable title and often stupid text that hardly corresponded to the entered query.
I photographed an example of such a request in the following image and identified the problem spot.

Moreover, the target address (URL) of the snippet for almost all requests led to the top of the main page, without even anchoring its section in the address relevant to the current request.
Well, let's say, if the request were about the exchange rate and the corresponding section would be present on the target landing page, it would be logical to anchor the link to the section with some hash like monobank.ua/#kurs-valut with the canonization of the same anchored URL so that the search robot would understand that the landing page has several landing points for the corresponding search phrases that would be registered by regular SEOs in the anchor text of links affixed by them somewhere on the site or outside the site, for example, in social networks.
Otherwise, it looked as if the site developers assigned the main page the role of a multi-section landing page, but they didn’t tell the SEO service providers, and they put promotional links with the planned anchor text, but without the section anchors. As a result, all the links for different types of requests seemed to lie at the starting point of the entry of the main page and inevitably received a single snippet with a heading relating to the main section of the main page.
Small digression
Just in case, I'll show in the next picture an example of HTML markup, how semantic layout is used to solve the issues of multiple landing points on a single landing page of the site.

Of course, this scheme will work provided that we put links to the landing page with an anchor corresponding to the information case. I.e:
- monobank.ua - basic information;
- monobank.ua/#kurs-valut - about exchange rates;
- monobank.ua/#otkryt-schet - about opening an account;
- monobank.ua/#kreditnaja-karta - about credit cards.
But back to the discovered jamb SEO
Although the mistake is not so serious, the main flow of customers still goes through the mobile application, nevertheless, due to this error, the bank loses some of the search traffic. Because search users are divided into 2 types - the rushing majority and the leisurely minority:
- the former read only the headers of the snippets and click them if the meaning of the header and the entered request match;
- the second carefully read the title and the text under it and also click only if the meaning coincides.
It is clear that the meaning of the message in the ossified search snippet for the bank page coincided only with a very small percentage of requests. It was necessary to understand where the mistake was made.
View the markup of the master page
I opened the main page of the bank using the link from the snippet. In the source code of this page, there was a single <h1> tag, usually used to write the main title of the page, which usually also ends up in the title of the snippet.
In addition, this main header tag was used in the page code earlier than the rest of the header <h> tags. So at first glance, it looked like it had no SEO errors.
I took a picture of that page and marked the position of the first two heading <h> tags on it.
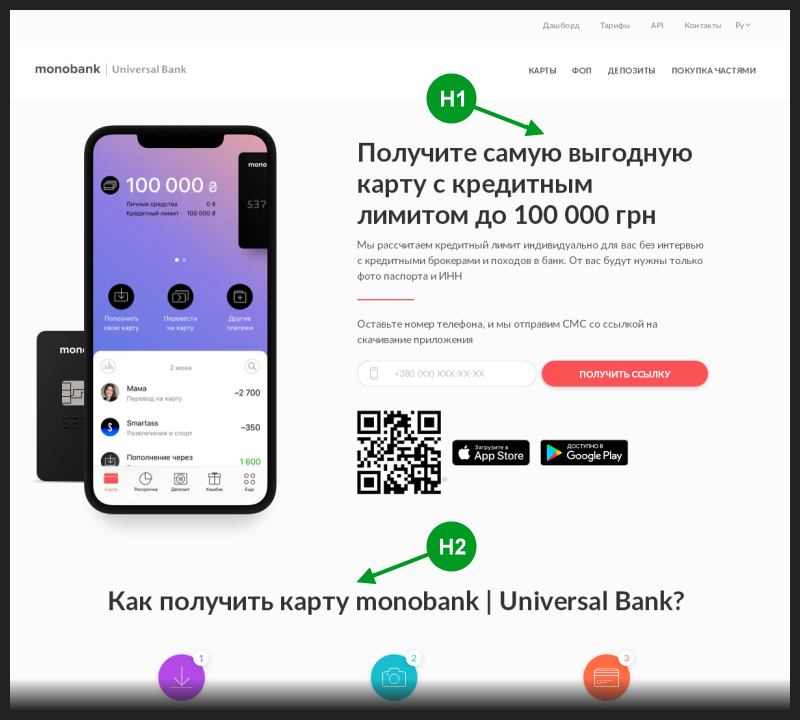
It was logical to expect that the <h1> tag will take the place of the title of the search snippet. But for some reason, a tag of a lower rank got there every time.
At first, I suggested that the case concerns only requests that include the name of the bank. It is not in the <h1> tag, but it is in the <h2> tag - therefore, that tag, despite having a lower rank, still gets the advantage of taking the snippet title.
However, this assumption is easy to test: you need to write a request exactly equal to the <h1> tag, and then this heading tag is guaranteed to have the right to occupy the snippet title based on an absolute match to the request. Which I did, while fixing the result in the next shot.

From the picture it follows that the search server still sees and understands the text of the <h1> tag, for some reason it does not consider it to be the main heading on the site of this bank. This is possible in 2 cases:
- either the SEO master added a specific semantic micro-markup to the page layout, which instructs another tag to become the main heading;
- or there is a so-called "problem of online constructors", when, due to the search non-optimality of building blocks, their text tags appear in different sections of an HTML document, and the main heading tag is omitted deeper than the non-main heading tag from the outline of its section.
I decided to check the first case first and opened the site in the structured data validation tool. However, only the Open Graph micro-markup was found, no hints of forced reassignment of tag semantics.
I captured this moment in the next picture.

Then I opened the source code of the problem page, formatted the spaces for easy study, removed the tag attributes for the same purpose, and then noted the essence of the problem in the next picture.

As a result, we have the state of affairs, interpreted below, from which I will write down an important conclusion in advance : after a month (this is approximately the average time for crawls by indexing robots) from launching the site, be sure to check for a few key queries how the search engine took the layout of your pages, i.e. which parts He actually indexed the content.
Interpretation of the result
Yandex, when parsing the page on the new Monobank domain, did not find the semantic layout (since everything is laid out with <div> s), and, having no instructions to analyze the implicit semantics, did not begin to guess by the tag classes, and when selecting the snippet title, it simply used the rule from the specification: tag <title> is the main title of the document.
Google, when parsing the same page, also did not find a semantic layout, but its artificial intelligence is able to analyze hidden semantic features, so it noticed four <div> s with an implicit semantic class contentindicating the contour of the section in the current marking situation. Therefore, the rule about the <title> tag was rejected, and the search engine used the rule from the specification about the section contours, trying to find a suitable section from the four declared. The first section is inappropriate because its heading tag is farther from the outline than the heading tag in sections 2, 3, and 4. From these more appropriate sections, the second section was selected based on its proximity to the beginning of the document. This is how its title got into the snippet.
In fact, the header selection logic for the snippet was identical for both search engines. It was just that Yandex selected the first heading tag from the first outline (the <head> tag is implicitly used) in the document, and Google chose the first heading tag from the semantically marked outline (it was clearly the <div class = "content"> tag).
This is that amazing feature of the search, called "undocumented" at the beginning of my investigation. The <h1> tag does not really have any significant importance. Based on the user's search query, a consistent section outline in the document and the first title in the outline are selected, not taking into account the used numerical level of the title.
Used materials
[1] One H1 or more - why is it right this way? , March 2020. Impera, SEO Documents. Excerpts from the specifications of the HTML standard show that writing one or more H1 tags on a page is considered correct in both cases.
[2] Monobank Mobile Application Promotion Case , August 2017 - March 2018. Promodo, Cases. On the example of the events used by the agency, it is described how the mobile application on iOS and Android was promoted using AdWords, Facebook, Instagram, Twitter, YouTube, and also optimized in the App Store and Google Play.