The note describes an experiment to create a small copy of an enterprise data warehouse with very limited specifications. Namely, based on a single-board computer Raspberry Pi.
The model and architecture will be simplified, but similar to an enterprise storage. The result is an assessment of the possibility of using the Raspberry Pi in the field of data processing and analysis.

# 1
The role of an experienced and strong player will be played by the Exadata X5 vehicle (one unit) of the Oracle corporation.
The data processing process includes the following steps:
- Reading from a 10.3 GB file - 350 million records in 90 minutes.
- Data processing and cleaning - 2 SQL queries and 15 minutes (with encryption of personal data 180 minutes).
- Loading measurements - 10 minutes.
- Downloading fact tables with 20 million new records - 5 SQL queries and 35 minutes.
Total integration of 350 million records in 2.5 hours, which is equivalent to 2.3 million records per minute or approximately 39 thousand raw data records per second.
# 2
The experimental opponent will be the Raspberry Pi 3 Model B + with a 4-core 1.4 GHz processor.
Sqlite3 is used as storage, files are read using PHP. The files and database are located on a 32GB class 10 SD card in the built-in reader. The backup is created on a 64 GB flash drive connected to USB.
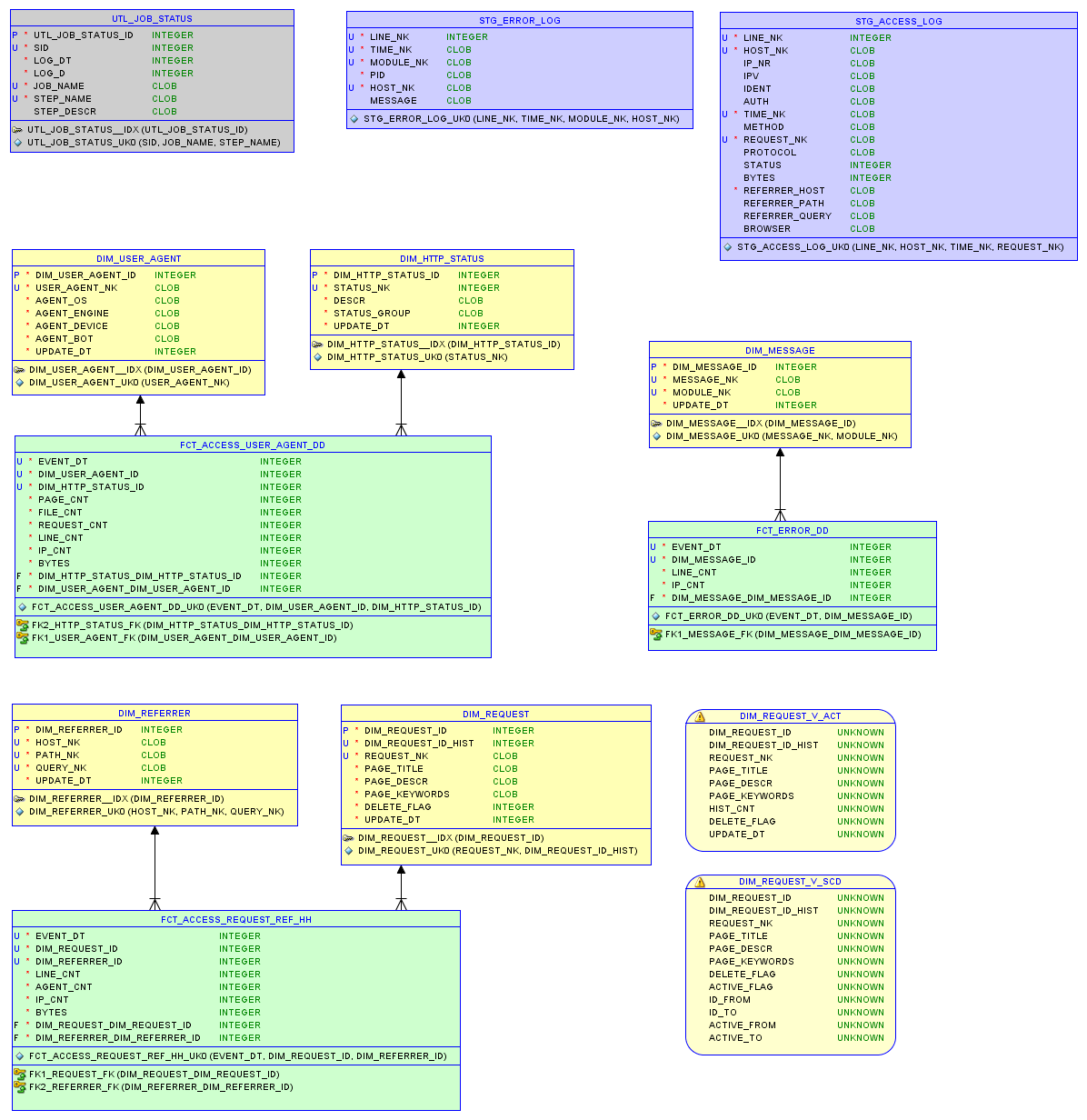
The data model in the sqlite3 relational database and reports are described in the article on small storage .
Data model
Test one
The source access.log file is 37 MB with 200 thousand entries.
- It took 340 seconds to read the log and write to the database.
- Loading measurements with 5 thousand records took 5 seconds.
- Loading fact tables with 90 thousand new records - 32 seconds.
Total , the integration of 200 thousand records took almost 7 minutes, which is equivalent to 28 thousand records per minute or 470 records of source data per second. The database occupies 7.5 MB; Only 8 SQL queries for data processing.
Second test
More active site file. The original access.log file is 67MB with 290K entries.
- It took 670 seconds to read the log and write to the database.
- Loading measurements with 25 thousand records lasted 8 seconds.
- Loading fact tables with 240 thousand new records - 80 seconds.
In total , the integration of 290 thousand records took just over 12 minutes, which is equivalent to 23 thousand records per minute or 380 raw data records per second. The database occupies 22.9 MB
Output
To obtain data in the form of a model that will allow for effective analysis, significant computational and material resources are required, and time in any case.
For example, one Exadata unit costs more than 100K. One Raspberry Pi costs 60 units.
They cannot be compared linearly, since with the increase in data volumes and reliability requirements, difficulties arise.
However, if we imagine a case where a thousand Raspberry Pi work in parallel, then, based on the experiment, they will process about 400 thousand records of raw data per second.
And if the solution for Exadata is optimized to 60 or 100 thousand records per second, then this is significantly less than 400 thousand. This confirms the inner feeling that the prices of enterprise solutions are too high.
In any case, the Raspberry Pi will do an excellent job with data processing and relational models of the appropriate scale.
Link
The home Raspberry Pi has been configured as a web server. I will describe this process in the next post.
You can experiment with the performance of the Raspberry Pi and the access.log file yourself at . The database model (DDL), loading procedures (ETL) and the database itself can be downloaded there. The idea is to quickly get an idea of the state of the site from the log with data from the last weeks.
Changes
Thanks to the comments, the bug in loading the Exadata file has been fixed and the numbers in the note have been corrected. Sqlloader is used for reading, some bug has removed the BINDSIZE and ROWS parameters. Due to unstable loading from a remote drive, the conventional method was chosen instead of the direct path, which could increase the speed by another 30-50%.